
Next-Gen GPU Cloud: Hội Tụ VM & Container Trên Kubernetes
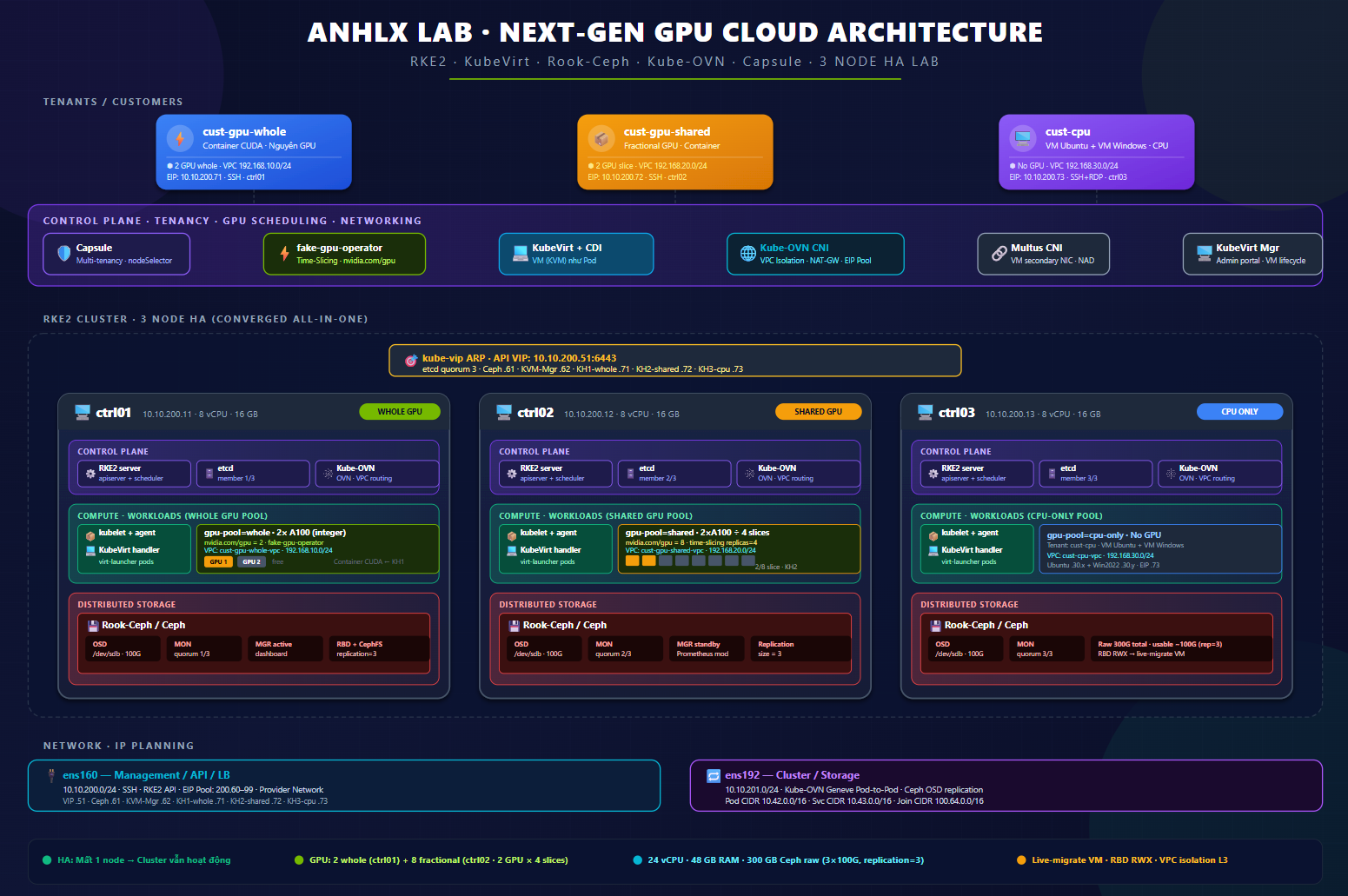
GPU Cloud thế hệ mới không chỉ bán GPU — mà bán compute linh hoạt theo nhu cầu: nguyên GPU cho AI training nặng, chia nhỏ GPU cho inference, không GPU cho workload thường. Tất cả trên một control plane, đồng thời phục vụ cả VM lẫn container với quota và mạng riêng từng tenant.
Mình build lab này để PoC toàn bộ business flow đó: 3 node Ubuntu 24.04 converged all-in-one, phân bổ theo tier GPU — ctrl01 (whole GPU: container CUDA nguyên GPU KH1), ctrl02 (fractional GPU: container CUDA 2 GPU chia nhỏ KH2), ctrl03 (CPU-only: VM Ubuntu + VM Windows KH3). CNI mình chọn Kube-OVN thay Cilium vì cần VPC/Subnet/NAT-Gateway native per tenant — đúng model cloud provider thương mại, không phải chỉ NetworkPolicy filter trên flat network.
Stack:
- RKE2 — Kubernetes HA, CIS-hardened, etcd quorum 3 node
- Rook-Ceph — distributed storage, RBD block-mode RWX cho VM live migration
- KubeVirt + CDI — chạy VM (KVM) như K8s workload, import Ubuntu/Windows image vào PVC
- fake-gpu-operator — giả lập GPU whole + time-sliced (lab; production: NVIDIA GPU Operator)
- Capsule — multi-tenancy hard isolation, custom Role per tenant, không cluster-admin
- Kube-OVN — CNI (thay Cilium), VPC/Subnet/NAT-Gateway/EIP per tenant
- kube-vip — VIP Kubernetes API HA
Phạm vi bài
- Mình lược bỏ một số thành phần — Kueue, Prometheus/Grafana, VolumeSnapshot — để tập trung vào demo business flow: cấp phát GPU linh hoạt bán cho 3 loại khách hàng với mạng riêng per tenant
- Stack công nghệ là những thứ mình đang quan tâm; kiến trúc và phân bổ resource theo hạ tầng mình có. Nếu áp dụng, bạn cần điều chỉnh spec VM, IP range, số node và các thành phần cho phù hợp với môi trường của mình
Mục lục
- 1. Tại sao Kubernetes cho Next-Gen GPU Cloud
- 2. Chuẩn bị Lab
- 3. Cài RKE2 HA Cluster
- 4. Kube-OVN + Multus
- 5. Rook-Ceph Distributed Storage
- 6. KubeVirt — chạy VM trên Kubernetes
- 7. KubeVirt Manager — Admin Portal
- 8. fake-gpu-operator — GPU Topology
- 9. Capsule — Multi-tenancy
- 10. Golden Image Templates
- 11. Demo: Onboard 3 Khách Hàng
- 12. Service URLs & Credentials
- 13. Lời kết
1. Tại sao Kubernetes cho Next-Gen GPU Cloud
1.1 OpenStack vs Kubernetes-native
OpenStack sinh ra trong kỷ nguyên VM-centric (2010–2018): GPU passthrough qua Nova hạn chế khi scale, còn muốn cung cấp song song VM lẫn container thì operator phải duy trì hai control plane riêng biệt — Nova cho VM, Zun (deprecated 2024) cho container.
Kubernetes giải quyết bằng một nền tảng duy nhất: KubeVirt chạy VM như K8s workload, chia sẻ cùng scheduler, storage và network với container. Khi AI workload cần fractional GPU, per-tenant GPU quota, live-migration — OpenStack lùi về phân khúc private cloud thuần VM, còn với bài toán phân phối GPU, Kubernetes là lựa chọn duy nhất hợp lý.
| Yêu cầu AI workload | OpenStack | Kubernetes-native |
|---|---|---|
| Cấp phát GPU cho container | Cần Magnum + Zun (deprecated), hoặc Nova GPU PCI | Built-in qua Device Plugin framework, GPU Operator |
| Fractional GPU (time-slice, MIG) | Không hỗ trợ native | GPU Operator + time-slicing ConfigMap, MIG, DRA |
| Multi-tenant GPU quota | Nova quota cho cores/RAM, không có cho GPU | ResourceQuota cho nvidia.com/gpu (Capsule enforce per-tenant) |
| VM + Container cùng platform | Chỉ VM (Nova). Container qua Zun (deprecated 2024) | KubeVirt cho VM + Pod cho container, cùng K8s API |
| Per-tenant VPC isolation | Neutron — VPC/Subnet/FloatingIP native | Kube-OVN — VPC/Subnet/NAT-Gateway/EIP native |
| GitOps / IaC | Heat templates, complex | Helm + ArgoCD/Flux, mọi config là YAML |
| AI ecosystem | Không có native integration | Kubeflow, KServe, Ray, vLLM, NIM — all native K8s |
1.2 Topology 3 nodes trong Lab — phân bổ theo loại khách hàng
GPU node (A100/H100) đắt hơn CPU node rất nhiều, cloud provider không đặt CPU-only workload lên GPU node — lãng phí tài nguyên. Lab phân bổ đúng pattern đó: mỗi node phục vụ một loại khách hàng.
| Node | IP | Roles K8s | Roles Ceph | GPU pool | Khách hàng phục vụ |
|---|---|---|---|---|---|
| ctrl01 | 10.10.200.11 | etcd, control-plane, worker | mon, osd | whole GPU — gpu-pool=whole, 2× simulated A100 |
KH1 (container nguyên GPU) |
| ctrl02 | 10.10.200.12 | etcd, control-plane, worker | mon, osd | shared GPU — gpu-pool=shared, 2× A100 chia 4 slice = 8 fractional |
KH2 (container GPU chia nhỏ) |
| ctrl03 | 10.10.200.13 | etcd, control-plane, worker | mon, osd | không — gpu-pool=cpu-only |
KH3 (VM Ubuntu + VM Windows) |
| VIP | 10.10.200.51 | API endpoint (kube-vip ARP) | — | — | — |
VPC network per tenant:
| Tenant | VPC | Subnet | VM/Container IP | EIP (floating) |
|---|---|---|---|---|
| cust-gpu-whole | cust-gpu-whole-vpc | 192.168.10.0/24 | 192.168.10.11 (pinned) | 10.10.200.71 |
| cust-gpu-shared | cust-gpu-shared-vpc | 192.168.20.0/24 | 192.168.20.11 (pinned) | 10.10.200.72 |
| cust-cpu | cust-cpu-vpc | 192.168.30.0/24 | dynamic (DHCP) | 10.10.200.73 |
Capsule inject nodeSelector per tenant để workload land đúng pool. Kube-OVN cung cấp VPC routing isolation — tenant A không thể reach VPC của tenant B ở L3.
2. Chuẩn bị Lab
3 VM Ubuntu 24.04.4 trên ESXi, cấu hình đồng nhất: 8 vCPU / 16 GB RAM / 200 GB OS / 100 GB Ceph OSD / ens160 (mgmt) + ens192 (cluster/storage).
ESXi: Expose hardware assisted virtualization to the guest OS = true (VM Options → CPU) — bắt buộc để KVM nested chạy được.
ctrl01: 10.10.200.11 | ctrl02: 10.10.200.12 | ctrl03: 10.10.200.13
VIP K8s API: 10.10.200.51
EIP pool 10.10.200.60-99:
.61 Ceph dashboard | .62 KubeVirt Manager
.71 cust-gpu-whole | .72 cust-gpu-shared | .73 cust-cpu
Service CIDR: 10.43.0.0/16 | DNS: 10.43.0.10 | Pod CIDR (Kube-OVN): 10.16.0.0/16
Join CIDR (Kube-OVN): 100.64.0.0/16
Mình chạy block chuẩn bị OS sau trên cả 3 node:
# Swap off (bắt buộc cho Kubernetes)
swapoff -a
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
# Disable ufw và apparmor (conflict với KVM nested)
systemctl disable --now ufw apparmor
# Chrony — Ceph yêu cầu clock skew < 50ms giữa các mon
apt update && apt install -y chrony open-vm-tools
# Tắt VMware Tools time sync persistently — ghi vào tools.conf để giữ qua reboot
mkdir -p /etc/vmware-tools
tee /etc/vmware-tools/tools.conf <<'EOF'
[vmware-tools]
disable-timesync = true
EOF
systemctl restart open-vm-tools
# Cấu hình Chrony với makestep -1 — step bất kỳ lúc nào lệch > 1s, không giới hạn số lần
tee /etc/chrony/chrony.conf <<'EOF'
server vn.pool.ntp.org iburst minpoll 4 maxpoll 6
makestep 1.0 -1
maxdistance 1.0
driftfile /var/lib/chrony/chrony.drift
rtcsync
EOF
systemctl restart chronyd
chronyc makestep
chronyc tracking | grep -E "System time|Leap status"
# Kernel modules
tee /etc/modules-load.d/k8s.conf <<EOF
br_netfilter
overlay
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
geneve
openvswitch
EOF
modprobe br_netfilter overlay ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack geneve openvswitch
# KVM nested (bắt buộc cho KubeVirt)
modprobe kvm_intel nested=1
echo "options kvm_intel nested=1" > /etc/modprobe.d/kvm-intel.conf
cat /sys/module/kvm_intel/parameters/nested # phải ra: Y
# sysctl
tee /etc/sysctl.d/99-k8s-ceph-kubevirt.conf <<EOF
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.default.rp_filter = 0
vm.swappiness = 0
vm.overcommit_memory = 1
vm.max_map_count = 524288
fs.inotify.max_user_instances = 8192
fs.inotify.max_user_watches = 524288
fs.file-max = 2097152
kernel.pid_max = 4194304
net.core.somaxconn = 32768
net.netfilter.nf_conntrack_max = 1000000
EOF
sysctl --system
# Packages
apt install -y \
curl wget vim git jq htop iotop \
nfs-common open-iscsi cryptsetup ceph-common \
qemu-guest-agent gnupg lsb-release apt-transport-https \
ca-certificates software-properties-common \
openvswitch-switch # OVS cho Kube-OVN
# Kube-OVN quản lý OVS bên trong container — host OVS phải dừng để tránh tranh lock socket
systemctl disable --now openvswitch-switch || true
# Ubuntu 24.04: phải dùng iptables-legacy — nftables mặc định làm KubeVirt rules fail im lặng
update-alternatives --set iptables /usr/sbin/iptables-legacy
update-alternatives --set ip6tables /usr/sbin/ip6tables-legacy
# /etc/hosts
tee -a /etc/hosts <<EOF
10.10.200.11 ctrl01
10.10.200.12 ctrl02
10.10.200.13 ctrl03
10.10.200.51 k8s-api.anhlx.lab
EOF
# DNSSEC mặc định gây SERVFAIL sau khi Kube-OVN enslaves ens160 vào br-provider — tắt đi
mkdir -p /etc/systemd/resolved.conf.d
tee /etc/systemd/resolved.conf.d/dns.conf <<EOF
[Resolve]
DNS=8.8.8.8
DNSSEC=no
EOF
systemctl restart systemd-resolved
3. Cài RKE2 HA Cluster
Mình bootstrap ctrl01 trước, sau đó join ctrl02 và ctrl03.
3.1 Bootstrap node đầu tiên (ctrl01)
Tạo config trước khi install — quan trọng vì RKE2 sẽ apply manifests trong /var/lib/rancher/rke2/server/manifests/ ngay khi start:
mkdir -p /etc/rancher/rke2 /var/lib/rancher/rke2/server/manifests
tee /etc/rancher/rke2/config.yaml <<EOF
write-kubeconfig-mode: "0644"
token: "Sup3rSecr3tT0ken-Lab-2026"
# Node-specific
node-name: "ctrl01"
node-ip: "10.10.200.11"
advertise-address: "10.10.200.11"
# TLS SAN — bao gồm VIP để client kubectl tin
tls-san:
- "10.10.200.51"
- "k8s-api.anhlx.lab"
- "ctrl01"
- "ctrl02"
- "ctrl03"
- "10.10.200.11"
- "10.10.200.12"
- "10.10.200.13"
# CNI = none — Kube-OVN tự cài sau khi cluster up
cni: none
# Disable components mặc định không dùng
disable:
- rke2-ingress-nginx
- rke2-snapshot-validation-webhook
# CIDR
cluster-cidr: "10.42.0.0/16"
service-cidr: "10.43.0.0/16"
cluster-dns: "10.43.0.10"
# Etcd snapshot
etcd-snapshot-schedule-cron: "0 */6 * * *"
etcd-snapshot-retention: 28
EOF
Tạo kube-vip manifest cho VIP API:
tee /var/lib/rancher/rke2/server/manifests/kube-vip.yaml <<EOF
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-vip
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: system:kube-vip-role
rules:
- apiGroups: [""]
resources: ["services", "services/status", "nodes", "endpoints"]
verbs: ["list","get","watch","update","patch"]
- apiGroups: ["coordination.k8s.io"]
resources: ["leases"]
verbs: ["list","get","watch","update","create"]
- apiGroups: ["discovery.k8s.io"]
resources: ["endpointslices"]
verbs: ["list","get","watch","update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:kube-vip-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-vip-role
subjects:
- kind: ServiceAccount
name: kube-vip
namespace: kube-system
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kube-vip-ds
namespace: kube-system
labels:
app.kubernetes.io/name: kube-vip-ds
app.kubernetes.io/version: v0.9.0
spec:
selector:
matchLabels:
app.kubernetes.io/name: kube-vip-ds
template:
metadata:
labels:
app.kubernetes.io/name: kube-vip-ds
app.kubernetes.io/version: v0.9.0
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-role.kubernetes.io/control-plane
operator: Exists
containers:
- name: kube-vip
image: ghcr.io/kube-vip/kube-vip:v0.9.0
imagePullPolicy: IfNotPresent
args:
- manager
env:
- name: vip_arp
value: "true"
- name: port
value: "6443"
- name: vip_cidr
value: "32"
- name: cp_enable
value: "true"
- name: cp_namespace
value: kube-system
- name: vip_ddns
value: "false"
- name: svc_enable
value: "true"
- name: vip_leaderelection
value: "true"
- name: vip_leaseduration
value: "15"
- name: vip_renewdeadline
value: "10"
- name: vip_retryperiod
value: "2"
- name: address
value: "10.10.200.51"
securityContext:
capabilities:
add: ["NET_ADMIN","NET_RAW","SYS_TIME"]
hostNetwork: true
serviceAccountName: kube-vip
tolerations:
- effect: NoSchedule
operator: Exists
- effect: NoExecute
operator: Exists
EOF
Thêm ConfigMap IP pool để kube-vip biết range cấp cho LoadBalancer services:
tee /var/lib/rancher/rke2/server/manifests/kube-vip-configmap.yaml <<EOF
apiVersion: v1
kind: ConfigMap
metadata:
name: kubevip
namespace: kube-system
data:
range-global: "10.10.200.61-10.10.200.65"
EOF
Cài và start RKE2:
curl -sfL https://get.rke2.io | INSTALL_RKE2_VERSION=v1.35.4+rke2r1 sh -
systemctl enable --now rke2-server.service
# Theo dõi log đến khi node khởi động xong (mất ~2-3 phút)
# Node sẽ ở trạng thái NotReady vì chưa có CNI — expected, Kube-OVN sẽ fix ở section 4
journalctl -u rke2-server -f
Trong khi chờ, setup kubectl:
cp /etc/rancher/rke2/rke2.yaml ~/rke2.yaml
chown $(id -u):$(id -g) ~/rke2.yaml
export KUBECONFIG=~/rke2.yaml
export PATH=$PATH:/var/lib/rancher/rke2/bin
echo 'export KUBECONFIG=~/rke2.yaml' >> ~/.bashrc
echo 'export PATH=$PATH:/var/lib/rancher/rke2/bin' >> ~/.bashrc
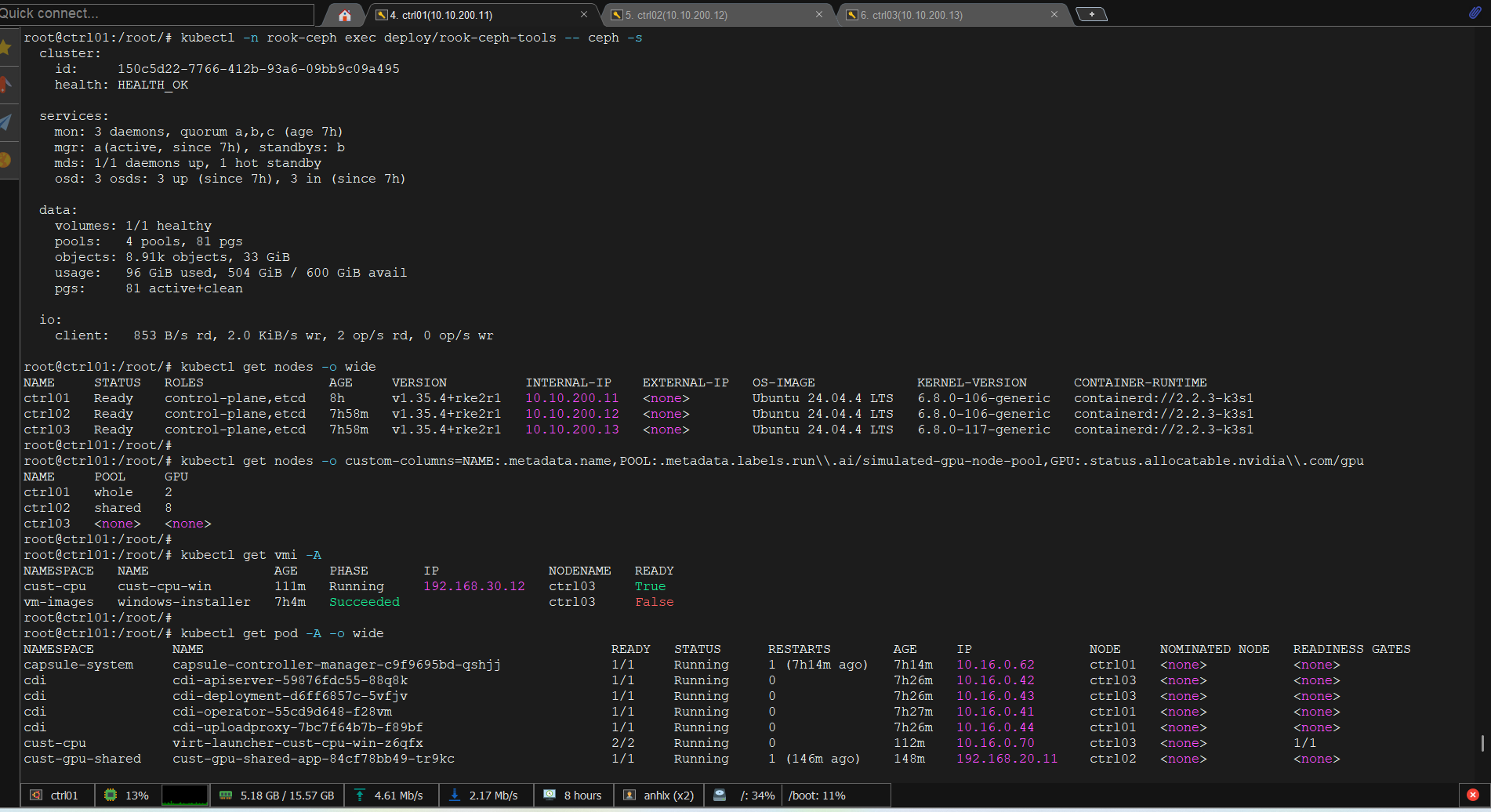
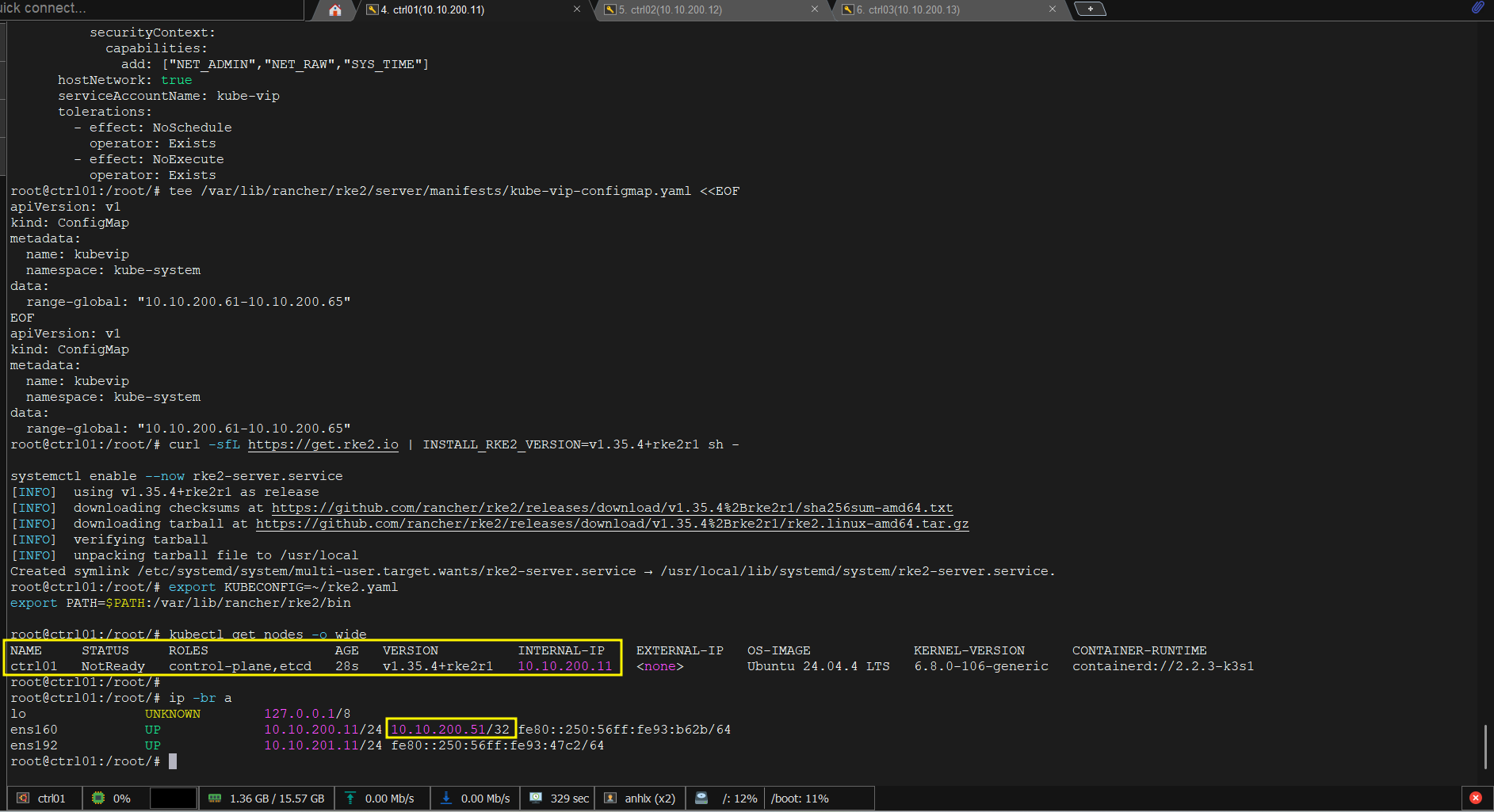
kubectl get nodes -o wide
# NAME STATUS ROLES AGE VERSION
# ctrl01 NotReady control-plane,etcd 2m v1.35.4+rke2r1
# NotReady là expected — chưa có CNI
3.2 Join ctrl02, ctrl03
Mình chạy lệnh sau trên ctrl02 (ctrl03 tương tự, chỉ đổi IP thành 10.10.200.13):
mkdir -p /etc/rancher/rke2
tee /etc/rancher/rke2/config.yaml <<EOF
server: https://10.10.200.51:9345
token: "Sup3rSecr3tT0ken-Lab-2026"
node-name: "ctrl02" # ctrl03 → "ctrl03"
node-ip: "10.10.200.12" # ctrl03 → "10.10.200.13"
advertise-address: "10.10.200.12" # ctrl03 → "10.10.200.13"
tls-san:
- "10.10.200.51"
- "k8s-api.anhlx.lab"
- "ctrl02" # ctrl03 → "ctrl03"
cni: none
disable:
- rke2-ingress-nginx
- rke2-snapshot-validation-webhook
EOF
curl -sfL https://get.rke2.io | INSTALL_RKE2_VERSION=v1.35.4+rke2r1 sh -
systemctl enable --now rke2-server.service
journalctl -u rke2-server -f
3.3 Verify cluster HA
Từ ctrl01:
kubectl get nodes -o wide
# NAME STATUS ROLES AGE VERSION
# ctrl01 NotReady control-plane,etcd 5m v1.35.4+rke2r1
# ctrl02 NotReady control-plane,etcd 2m v1.35.4+rke2r1
# ctrl03 NotReady control-plane,etcd 1m v1.35.4+rke2r1
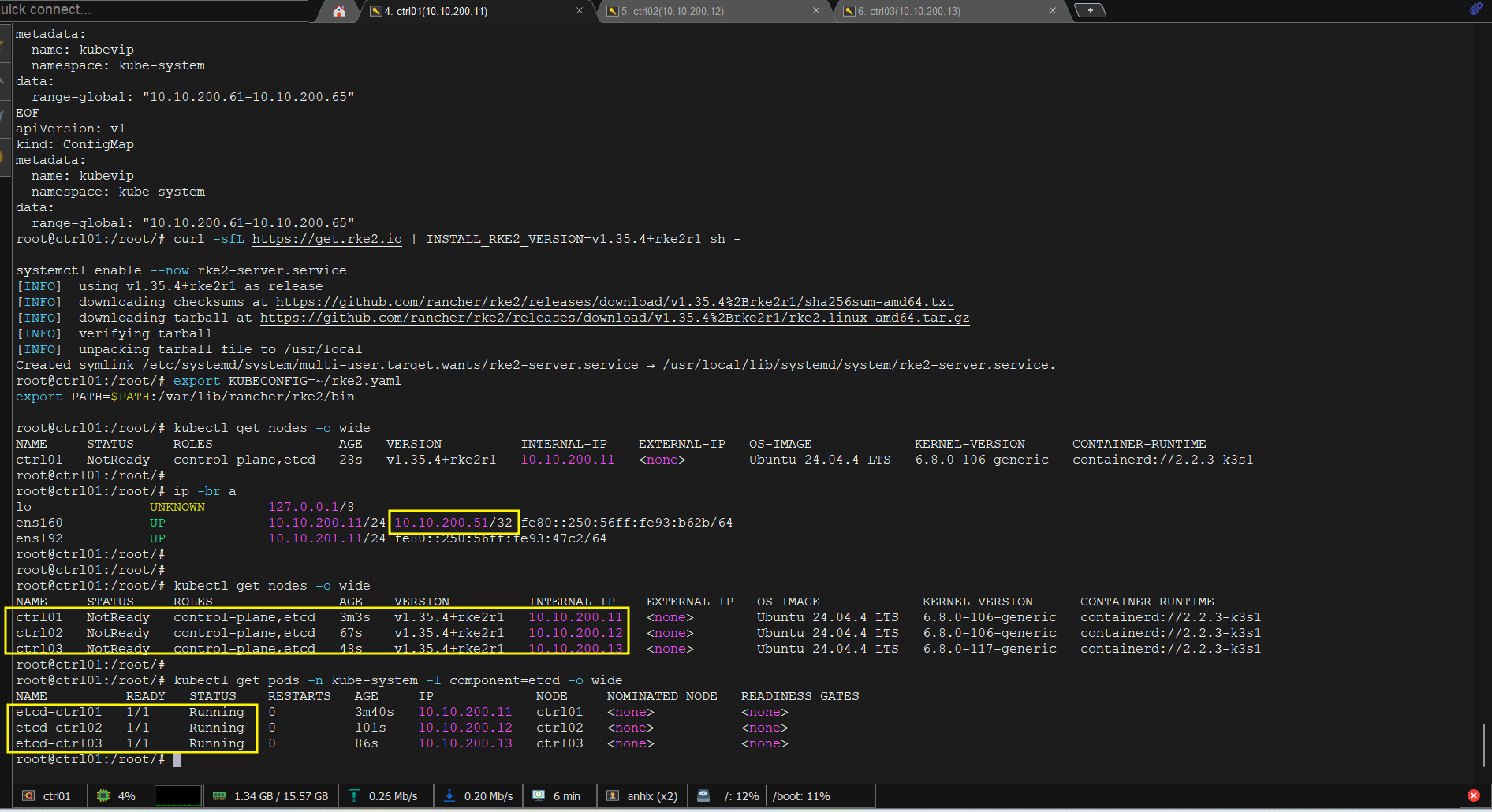
# Verify etcd quorum
kubectl get pods -n kube-system -l component=etcd -o wide
# Phải thấy 3 etcd pod trên 3 node
4. Kube-OVN + Multus
Kube-OVN đóng vai trò CNI thay Cilium — lý do chọn là VPC/Subnet/NAT-Gateway native, cần cho isolation per tenant ở section 11. Phần này cài CNI, kết nối vào mạng vật lý, setup EIP pool dùng chung. Sau bước này nodes chuyển sang Ready.
# Helm 3
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh
helm version
Cài Kube-OVN v1.13.0:
export KUBEOVN_VERSION=v1.13.0
export JOIN_CIDR="100.64.0.0/16" # Join subnet cho inter-node traffic của Kube-OVN
export IFACE="ens160" # Interface kết nối provider network
export ENABLE_SSL="false"
wget -q https://raw.githubusercontent.com/kubeovn/kube-ovn/${KUBEOVN_VERSION}/dist/images/install.sh
chmod +x install.sh
bash install.sh 2>&1 | tee /tmp/kubeovn-install.log
- Cuối output có
Error from server (NotFound): deployments.apps "coredns" not found— script cố restartcorednsnhưng RKE2 dùngrke2-coredns. Harmless.ovn-defaultsubnet CIDR sẽ là10.16.0.0/16(hardcoded trong install.sh). RKE2cluster-cidr: 10.42.0.0/16bị bỏ qua khi Kube-OVN là CNI — Kube-OVN tự quản lý IPAM và routing qua OVN/OVS.
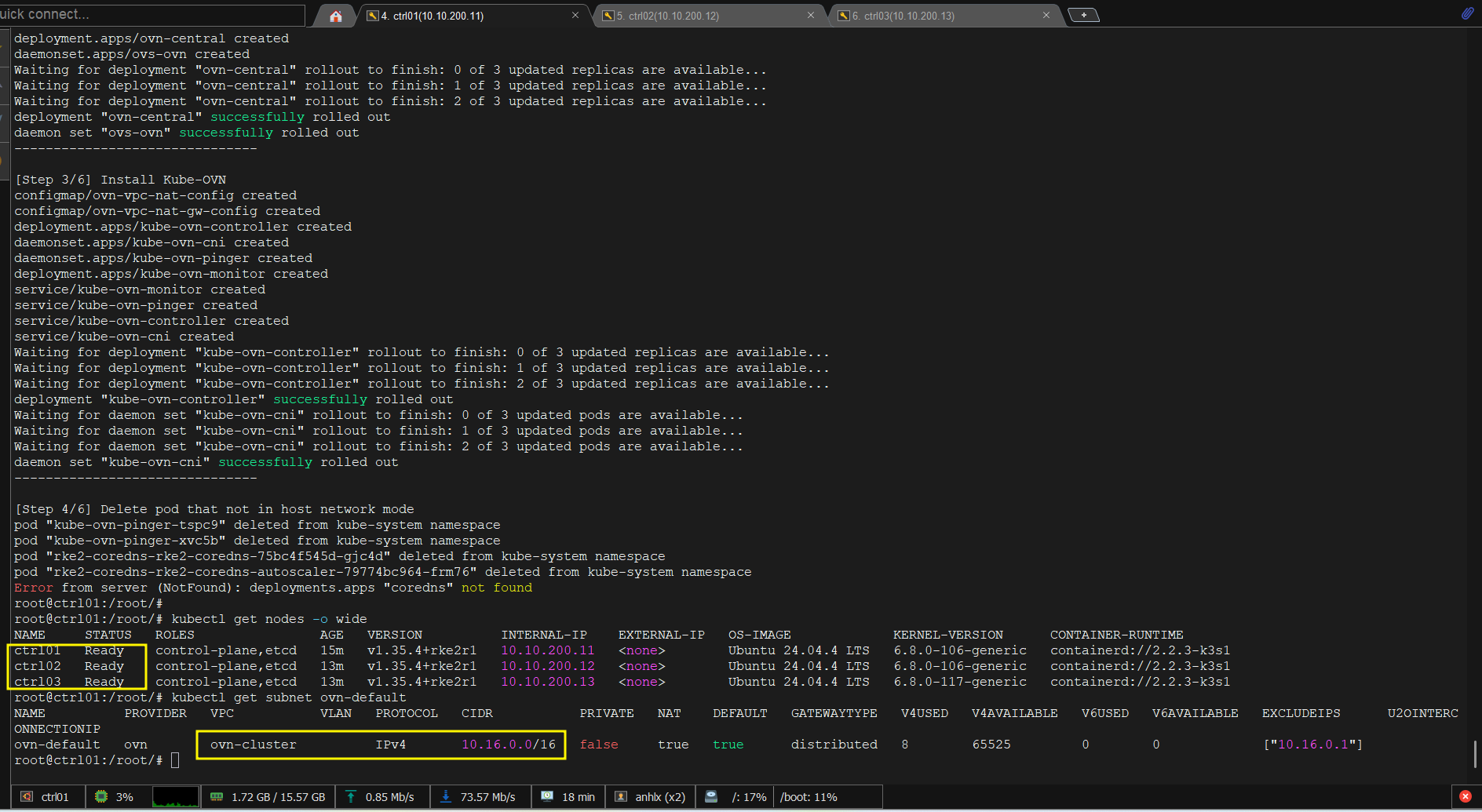
Sau khi Kube-OVN up, nodes chuyển sang Ready:
kubectl get nodes -o wide
# Verify default subnet đã tạo tự động
kubectl get subnet ovn-default
# NAME PROVIDER VPC PROTOCOL CIDR PRIVATE NAT
# ovn-default ovn ovn-cluster IPv4 10.16.0.0/16 false false
Provider Network — bridge Kube-OVN vào ens160, tạo OVS bridge br-provider trên mỗi node:
kubectl apply -f - <<EOF
apiVersion: kubeovn.io/v1
kind: ProviderNetwork
metadata:
name: provider
spec:
defaultInterface: ens160
---
apiVersion: kubeovn.io/v1
kind: Vlan
metadata:
name: vlan0
spec:
id: 0
provider: provider
---
apiVersion: kubeovn.io/v1
kind: Subnet
metadata:
name: ovn-provider
spec:
protocol: IPv4
vlan: vlan0
cidrBlock: 10.10.200.0/24
gateway: 10.10.200.1
excludeIps:
- 10.10.200.1
- 10.10.200.11..10.10.200.13
- 10.10.200.51
- 10.10.200.60..10.10.200.99
vpc: ovn-cluster
private: false
natOutgoing: false
EOF
NAD ovn-vpc-external-network — VpcNatGateway pod cần NIC thứ hai ra ngoài. Trước tiên cần cài CRD NetworkAttachmentDefinition (CRD này thường do Multus cung cấp, nhưng nếu chưa cài Multus thì apply thủ công):
kubectl apply -f - <<'EOF'
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: network-attachment-definitions.k8s.cni.cncf.io
spec:
group: k8s.cni.cncf.io
scope: Namespaced
names:
plural: network-attachment-definitions
singular: network-attachment-definition
kind: NetworkAttachmentDefinition
shortNames:
- net-attach-def
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
apiVersion:
type: string
kind:
type: string
metadata:
type: object
spec:
type: object
properties:
config:
type: string
EOF
Sau đó tạo NAD dùng macvlan trên br-provider với kube-ovn IPAM:
kubectl apply -f - <<EOF
apiVersion: k8s.cni.cncf.io/v1
kind: NetworkAttachmentDefinition
metadata:
name: ovn-vpc-external-network
namespace: kube-system
spec:
config: '{
"cniVersion": "0.3.0",
"type": "macvlan",
"master": "br-provider",
"mode": "bridge",
"ipam": {
"type": "kube-ovn",
"server_socket": "/run/openvswitch/kube-ovn-daemon.sock",
"provider": "ovn-vpc-external-network.kube-system"
}
}'
---
apiVersion: kubeovn.io/v1
kind: Subnet
metadata:
name: ovn-vpc-external-network
spec:
protocol: IPv4
provider: ovn-vpc-external-network.kube-system
cidrBlock: 10.10.200.0/24
gateway: 10.10.200.1
excludeIps:
- 10.10.200.1
- 10.10.200.11..10.10.200.13
- 10.10.200.51
- 10.10.200.60..10.10.200.99
natOutgoing: false
EOF
Verify:
kubectl get provider-networks.kubeovn.io provider
# NAME DEFAULT-INTERFACE READY
# provider ens160 true
Multus — cho phép VM gắn secondary NIC vào VPC subnet của tenant:
MULTUS_VERSION=v4.1.4
kubectl apply -f https://raw.githubusercontent.com/k8snetworkplumbingwg/multus-cni/${MULTUS_VERSION}/deployments/multus-daemonset-thick.yml
kubectl -n kube-system rollout status daemonset/kube-multus-ds
# daemon set "kube-multus-ds" successfully rolled out
5. Rook-Ceph Distributed Storage
Mình cài Rook-Ceph theo thứ tự: operator → CephCluster CR → pool và StorageClass.
5.1 Cài Rook Operator
ROOK_VERSION=v1.19.5
kubectl apply --server-side -f https://raw.githubusercontent.com/rook/rook/${ROOK_VERSION}/deploy/examples/crds.yaml
kubectl get crd cephclusters.ceph.rook.io
kubectl apply -f https://raw.githubusercontent.com/rook/rook/${ROOK_VERSION}/deploy/examples/common.yaml
kubectl apply -f https://raw.githubusercontent.com/rook/rook/${ROOK_VERSION}/deploy/examples/operator.yaml
kubectl -n rook-ceph rollout status deployment/rook-ceph-operator
# Rook v1.19+ bật ROOK_USE_CSI_OPERATOR=true mặc định nhưng CRD csi.ceph.io chưa install → CSI không lên được
kubectl -n rook-ceph patch configmap rook-ceph-operator-config --type=merge -p '{"data":{"ROOK_USE_CSI_OPERATOR":"false"}}'
# CSI CRDs cần thêm thủ công — không có trong crds.yaml của Rook v1.19
kubectl apply -f - <<EOF
---
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: cephconnections.csi.ceph.io
spec:
group: csi.ceph.io
names:
kind: CephConnection
listKind: CephConnectionList
plural: cephconnections
singular: cephconnection
scope: Namespaced
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
x-kubernetes-preserve-unknown-fields: true
subresources:
status: {}
---
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: clientprofiles.csi.ceph.io
spec:
group: csi.ceph.io
names:
kind: ClientProfile
listKind: ClientProfileList
plural: clientprofiles
singular: clientprofile
scope: Namespaced
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
x-kubernetes-preserve-unknown-fields: true
subresources:
status: {}
---
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: networkfences.csi.ceph.io
spec:
group: csi.ceph.io
names:
kind: NetworkFence
listKind: NetworkFenceList
plural: networkfences
singular: networkfence
scope: Cluster
versions:
- name: v1alpha1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
x-kubernetes-preserve-unknown-fields: true
subresources:
status: {}
EOF
5.2 Tạo CephCluster
kubectl apply -f - <<EOF
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
name: rook-ceph
namespace: rook-ceph
spec:
cephVersion:
image: quay.io/ceph/ceph:v19.2.3
allowUnsupported: false
dataDirHostPath: /var/lib/rook
skipUpgradeChecks: false
mon:
count: 3
allowMultiplePerNode: false
mgr:
count: 2
allowMultiplePerNode: false
modules:
- name: dashboard
enabled: true
- name: prometheus
enabled: true
dashboard:
enabled: true
ssl: false
monitoring:
enabled: true
network:
provider: host
crashCollector:
disable: false
cleanupPolicy:
confirmation: ""
resources:
mon:
requests:
cpu: 200m
memory: 512Mi
limits:
memory: 1Gi
osd:
requests:
cpu: 300m
memory: 1Gi
limits:
memory: 2Gi
mgr:
requests:
cpu: 200m
memory: 512Mi
limits:
memory: 1Gi
storage:
useAllNodes: true
useAllDevices: false
deviceFilter: "^sdb"
config:
osdsPerDevice: "1"
storeType: bluestore
placement:
all:
tolerations:
- operator: Exists
EOF
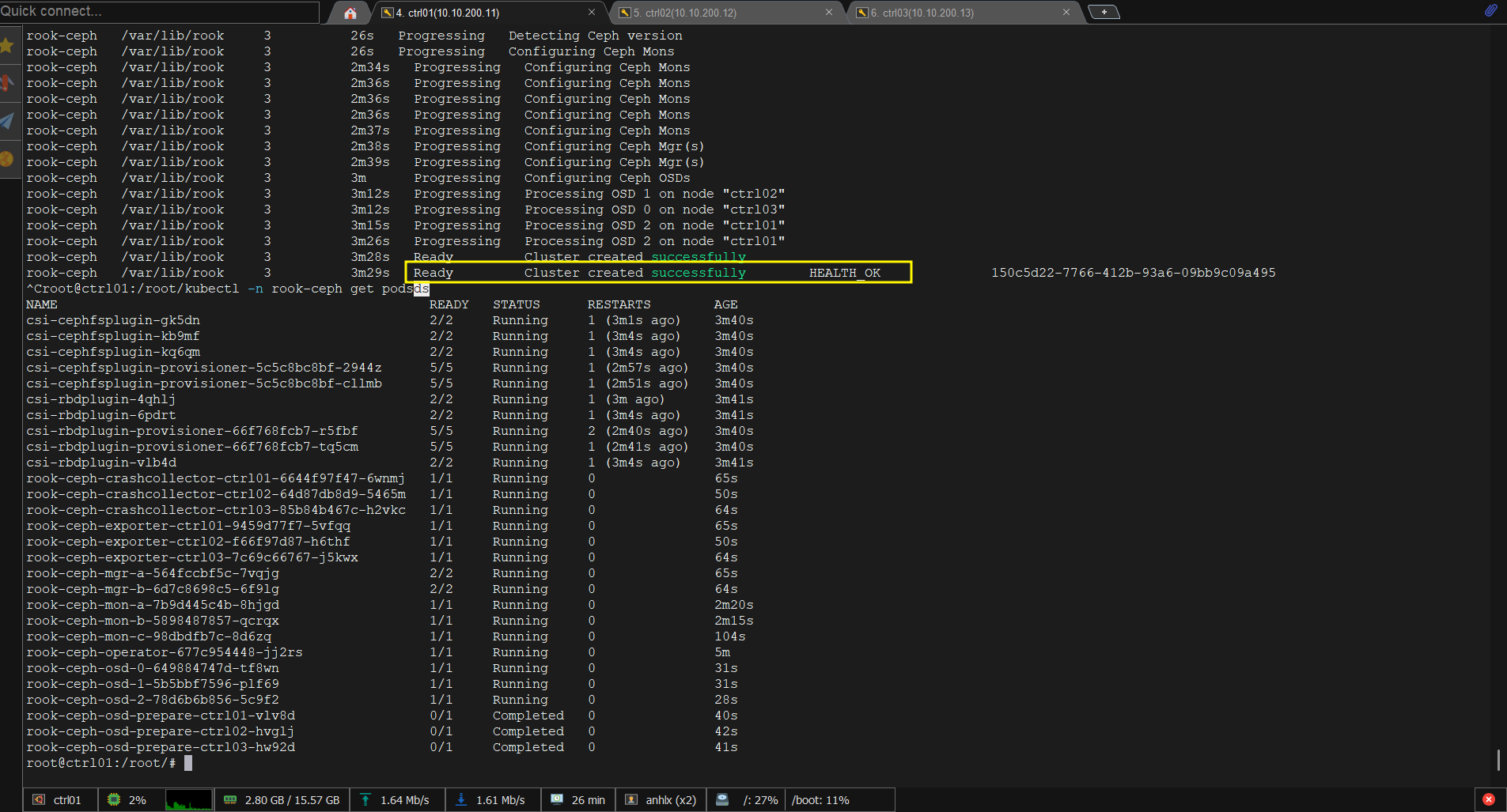
Theo dõi cluster lên:
kubectl -n rook-ceph get cephcluster
kubectl -n rook-ceph get pods
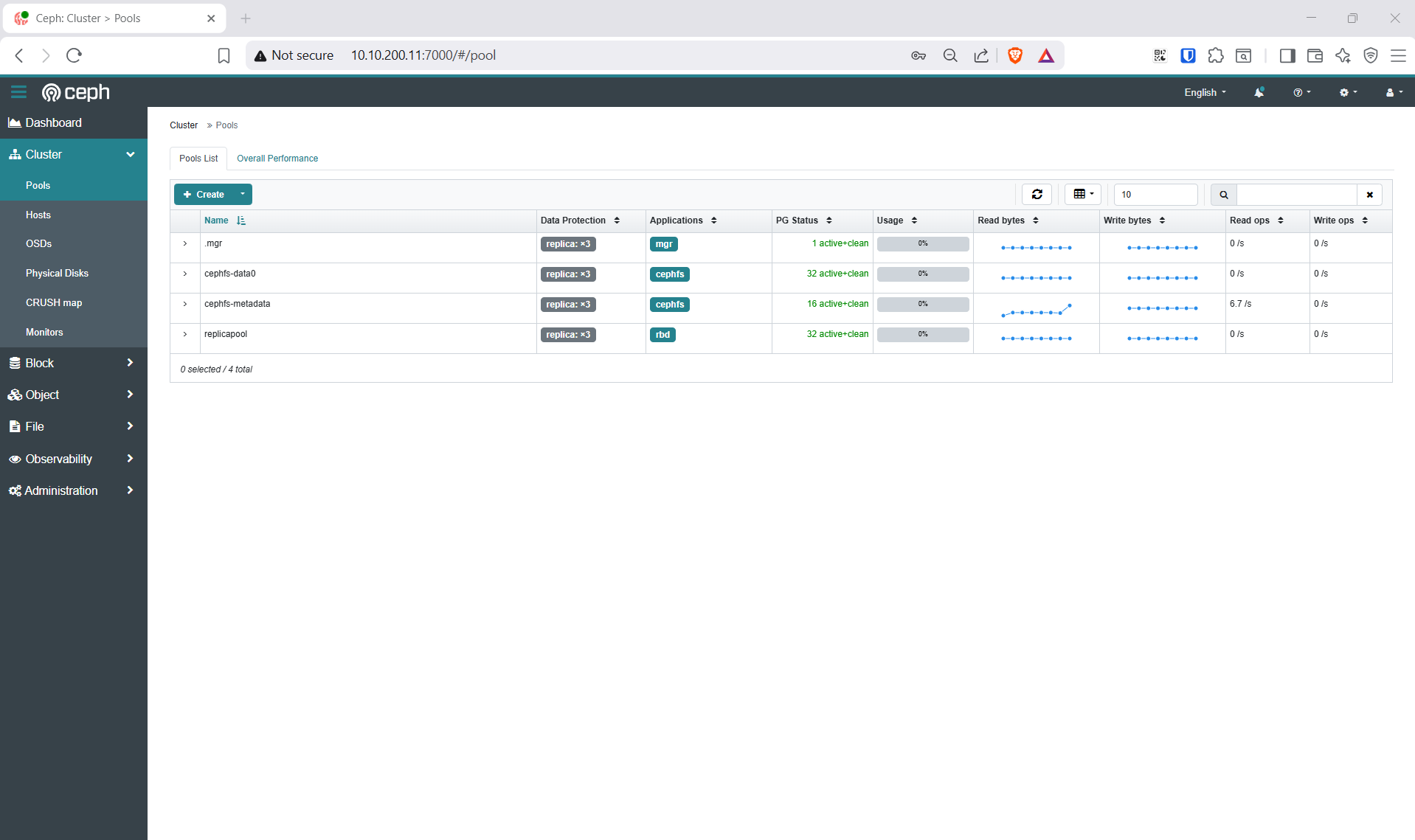
5.3 Tạo Pools + StorageClass (replication=3, RBD-RWX, CephFS)
Replication=3 đảm bảo an toàn dữ liệu khi mất 1 OSD. RBD block-mode RWX cho phép VM live migration.
kubectl apply -f - <<EOF
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: replicapool
namespace: rook-ceph
spec:
failureDomain: host
replicated:
size: 3
parameters:
pg_num: "32"
pgp_num: "32"
---
apiVersion: ceph.rook.io/v1
kind: CephFilesystem
metadata:
name: cephfs
namespace: rook-ceph
spec:
metadataPool:
failureDomain: host
replicated:
size: 3
dataPools:
- name: data0
failureDomain: host
replicated:
size: 3
preserveFilesystemOnDelete: true
metadataServer:
activeCount: 1
activeStandby: true
resources:
requests:
cpu: 200m
memory: 512Mi
limits:
memory: 1Gi
EOF
Tạo 3 StorageClass:
kubectl apply -f - <<EOF
---
# 1. RBD RWO — cho container thông thường (mặc định)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: rook-ceph.rbd.csi.ceph.com
parameters:
clusterID: rook-ceph
pool: replicapool
imageFormat: "2"
imageFeatures: layering,exclusive-lock,object-map,fast-diff,deep-flatten
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
csi.storage.k8s.io/fstype: ext4
allowVolumeExpansion: true
reclaimPolicy: Delete
---
# 2. RBD block-mode RWX — cho VM disk hỗ trợ live migration
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block-rwx
provisioner: rook-ceph.rbd.csi.ceph.com
parameters:
clusterID: rook-ceph
pool: replicapool
imageFormat: "2"
imageFeatures: layering
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
allowVolumeExpansion: true
reclaimPolicy: Delete
---
# 3. CephFS RWX — cho shared filesystem
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-cephfs
provisioner: rook-ceph.cephfs.csi.ceph.com
parameters:
clusterID: rook-ceph
fsName: cephfs
pool: cephfs-data0
csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
allowVolumeExpansion: true
reclaimPolicy: Delete
EOF
kubectl get sc
5.4 Ceph Toolbox
Deploy toolbox pod để có thể chạy ceph -s và các lệnh admin trực tiếp từ cluster:
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: rook-ceph-tools
namespace: rook-ceph
spec:
replicas: 1
selector:
matchLabels:
app: rook-ceph-tools
template:
metadata:
labels:
app: rook-ceph-tools
spec:
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: rook-ceph-tools
image: docker.io/rook/ceph:v1.19.5
command: ["/bin/bash"]
args: ["-m", "-c", "/usr/local/bin/toolbox.sh"]
env:
- name: ROOK_CEPH_USERNAME
valueFrom:
secretKeyRef:
name: rook-ceph-mon
key: ceph-username
- name: ROOK_CEPH_SECRET
valueFrom:
secretKeyRef:
name: rook-ceph-mon
key: ceph-secret
volumeMounts:
- mountPath: /etc/ceph
name: ceph-config
- name: mon-endpoint-volume
mountPath: /etc/rook
volumes:
- name: mon-endpoint-volume
configMap:
name: rook-ceph-mon-endpoints
items:
- key: data
path: mon-endpoints
- name: ceph-config
emptyDir: {}
EOF
kubectl -n rook-ceph rollout status deploy/rook-ceph-tools
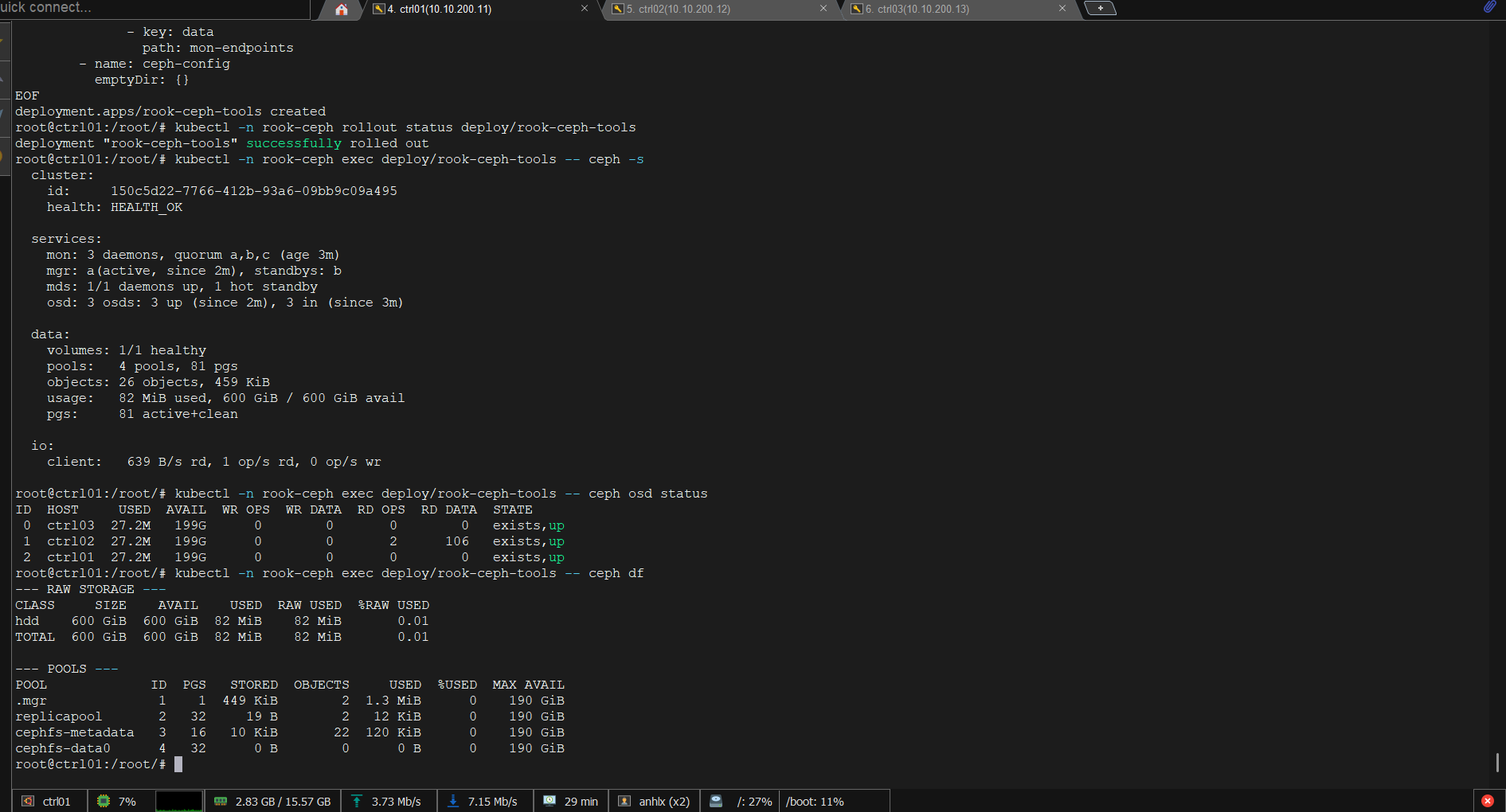
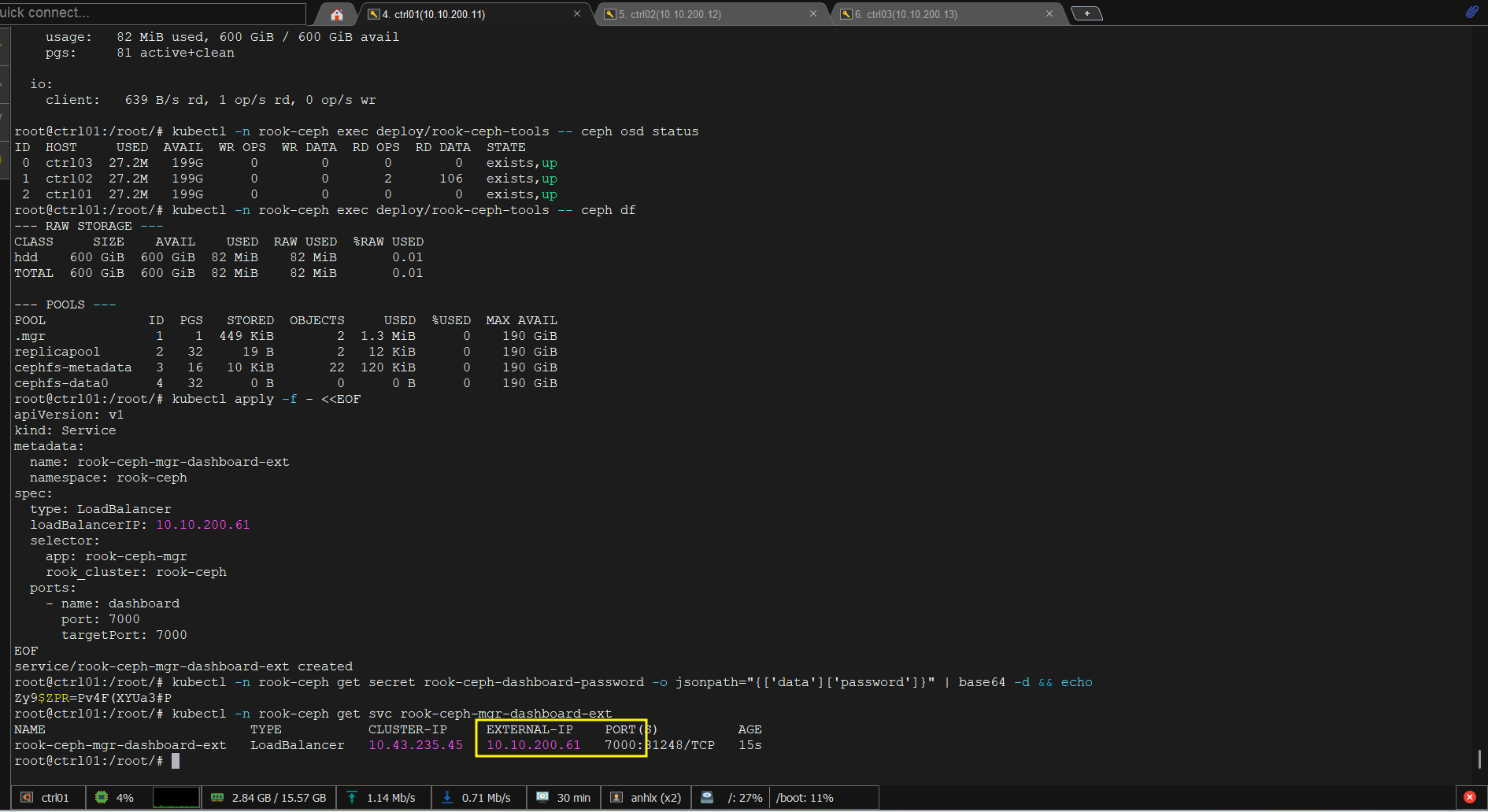
kubectl -n rook-ceph exec deploy/rook-ceph-tools -- ceph -s
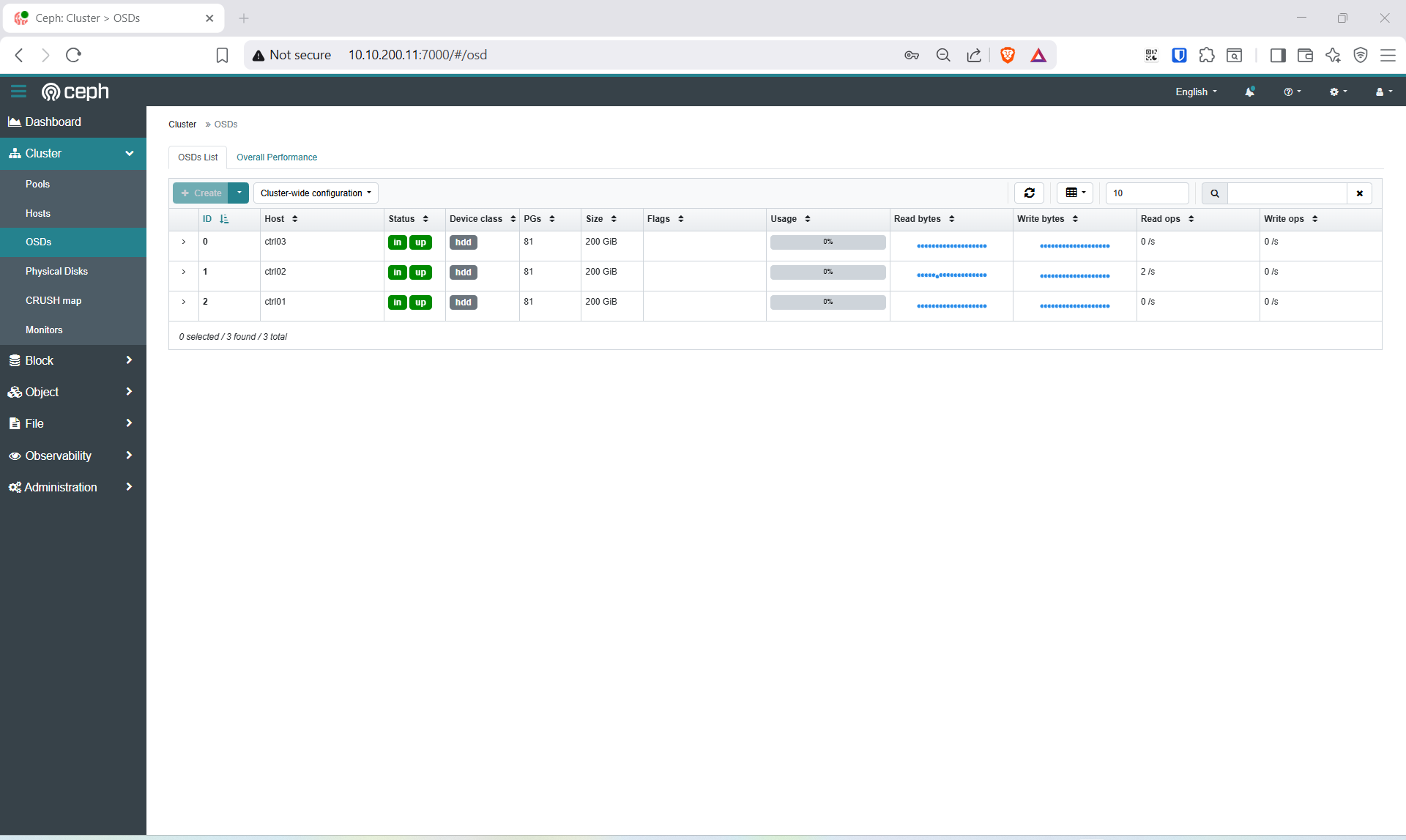
kubectl -n rook-ceph exec deploy/rook-ceph-tools -- ceph osd status
kubectl -n rook-ceph exec deploy/rook-ceph-tools -- ceph df
5.5 Ceph Dashboard
Mình expose Ceph Dashboard qua LoadBalancer — kube-vip sẽ announce IP 10.10.200.61 ra mạng (pool đã khai báo ở section 3.1):
kubectl apply -f - <<EOF
apiVersion: v1
kind: Service
metadata:
name: rook-ceph-mgr-dashboard-ext
namespace: rook-ceph
spec:
type: LoadBalancer
loadBalancerIP: 10.10.200.61
selector:
app: rook-ceph-mgr
rook_cluster: rook-ceph
ports:
- name: dashboard
port: 7000
targetPort: 7000
EOF
# Lấy password admin
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 -d && echo
# Lấy endpoint dashboard
kubectl -n rook-ceph get svc rook-ceph-mgr-dashboard-ext
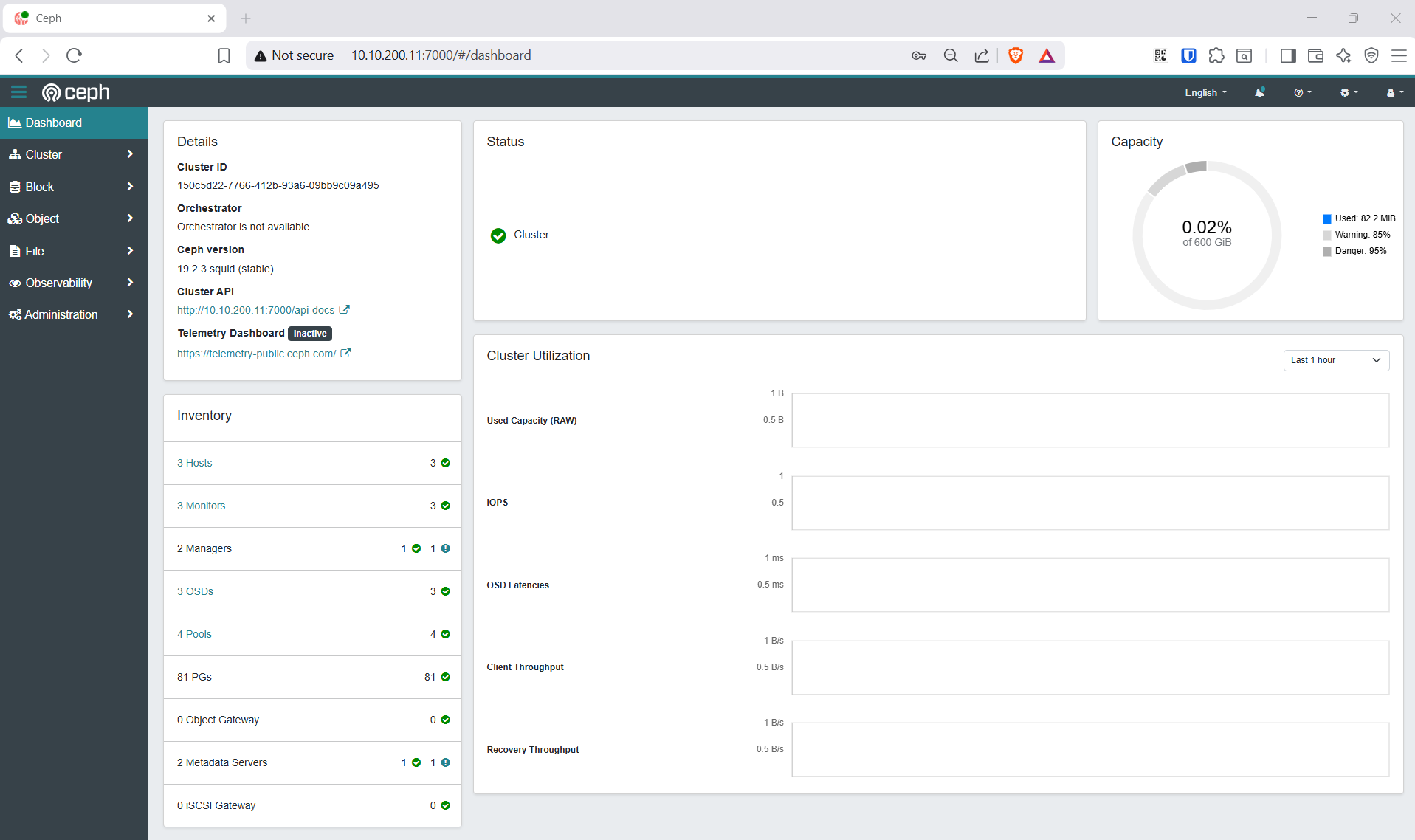
Truy cập http://10.10.200.61:7000 với user admin và password vừa lấy.
Lưu ý: Ceph tự redirect sang IP của active MGR node — đây là behavior bình thường, dashboard vẫn hoạt động đầy đủ.

6. KubeVirt — chạy VM trên Kubernetes
KubeVirt + CDI cho phép chạy VM KVM như K8s workload — cùng scheduler, storage và network với container.
# KubeVirt operator
KUBEVIRT_VERSION=v1.8.0
kubectl apply -f https://github.com/kubevirt/kubevirt/releases/download/${KUBEVIRT_VERSION}/kubevirt-operator.yaml
# KubeVirt CR — cấu hình cluster
kubectl apply -f - <<EOF
apiVersion: kubevirt.io/v1
kind: KubeVirt
metadata:
name: kubevirt
namespace: kubevirt
spec:
certificateRotateStrategy: {}
configuration:
developerConfiguration:
featureGates:
- GPU
- HostDevices
- LiveMigration
- VMLiveUpdateFeatures
- ExpandDisks
- HotplugVolumes
- HotplugNICs
- VMExport
- Sysprep
smbios:
family: Lab-CloudVM
manufacturer: GPU-Cloud-Lab
product: KubeVirt
sku: lab-2026
version: "1.0"
imagePullPolicy: IfNotPresent
workloadUpdateStrategy:
workloadUpdateMethods:
- LiveMigrate
EOF
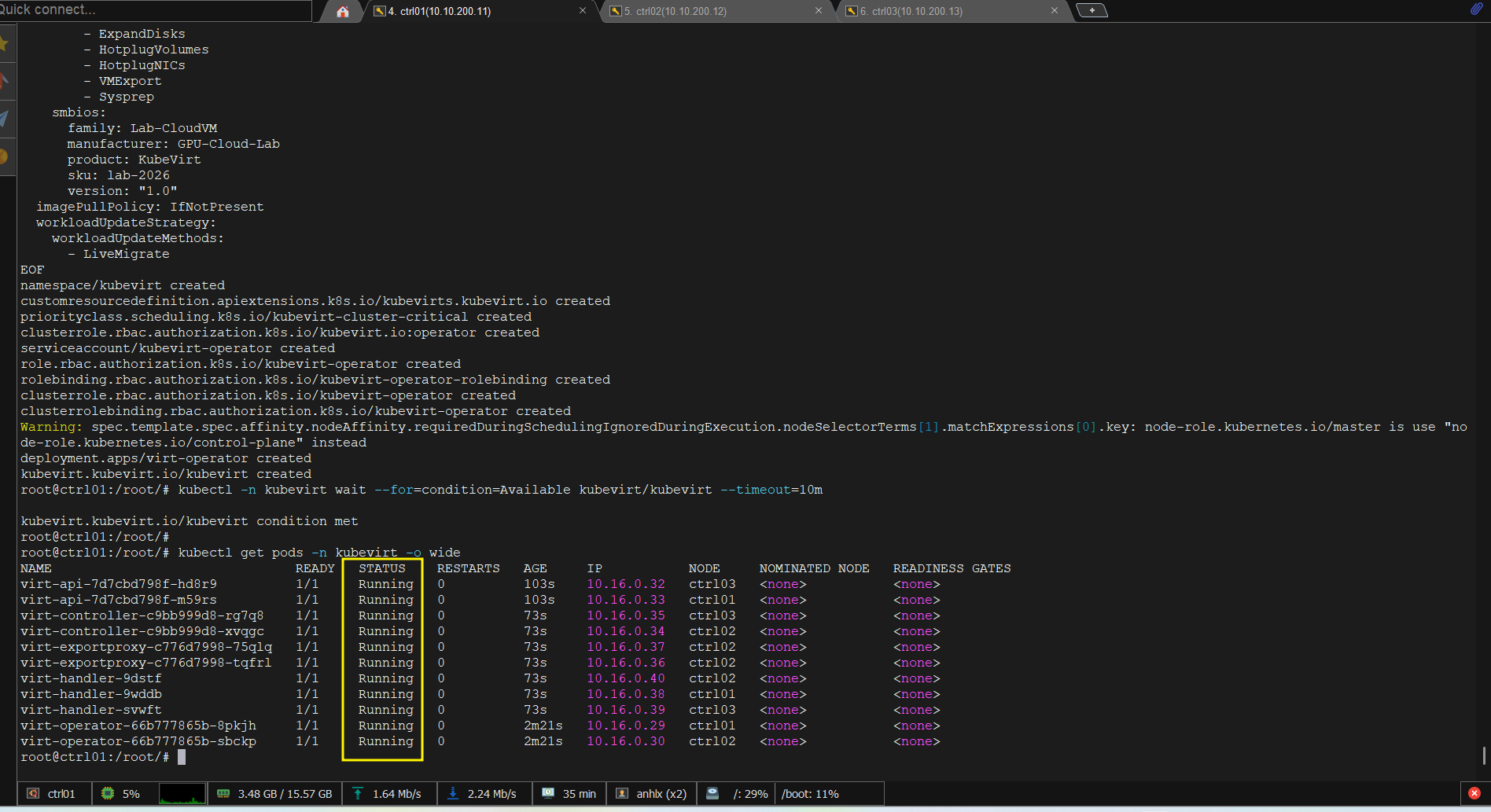
kubectl -n kubevirt wait --for=condition=Available kubevirt/kubevirt --timeout=10m
kubectl get pods -n kubevirt
# virt-api-xxxxx 1/1 Running
# virt-controller-xxxxx 1/1 Running (x2)
# virt-handler-xxxxx 1/1 Running (x3)
# virt-operator-xxxxx 1/1 Running (x2)
Cài CDI:
CDI_VERSION=v1.65.0
kubectl apply -f https://github.com/kubevirt/containerized-data-importer/releases/download/${CDI_VERSION}/cdi-operator.yaml
kubectl apply -f https://github.com/kubevirt/containerized-data-importer/releases/download/${CDI_VERSION}/cdi-cr.yaml
kubectl -n cdi patch cdi cdi --type merge --patch '
{
"spec": {
"config": {
"scratchSpaceStorageClass": "rook-ceph-block"
}
}
}'
kubectl -n cdi wait --for=condition=Available cdi/cdi --timeout=5m
kubectl get pods -n cdi
Cài virtctl CLI:
KUBEVIRT_VERSION=v1.8.0
curl -L -o virtctl https://github.com/kubevirt/kubevirt/releases/download/${KUBEVIRT_VERSION}/virtctl-${KUBEVIRT_VERSION}-linux-amd64
chmod +x virtctl
mv virtctl /usr/local/bin/
virtctl version
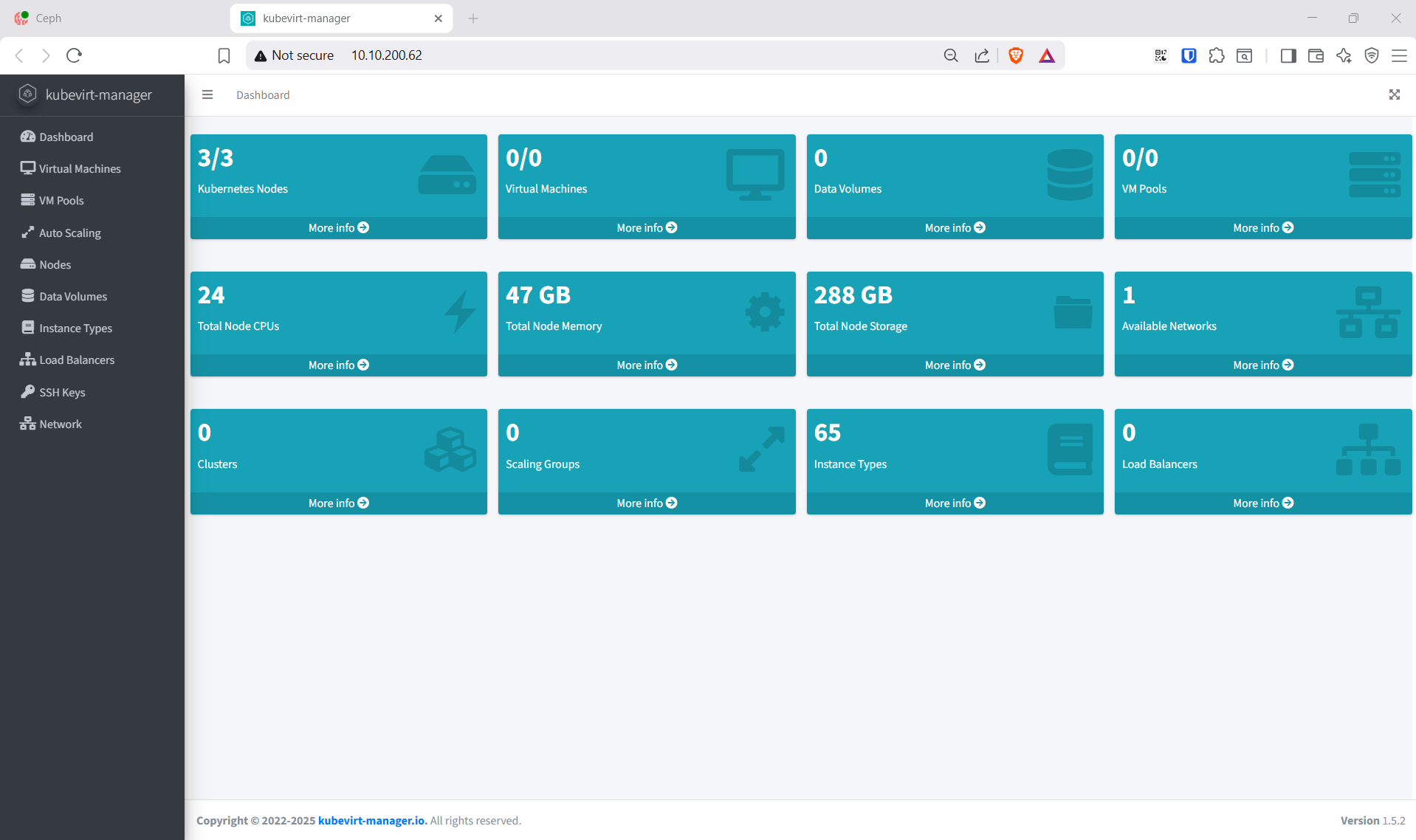
7. KubeVirt Manager — Admin Portal
Admin UI cho VM lifecycle (start/stop/console/migrate).
kubectl apply -f - <<EOF
apiVersion: v1
kind: Namespace
metadata:
name: kubevirt-manager
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kubevirt-manager
namespace: kubevirt-manager
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubevirt-manager
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: kubevirt-manager
namespace: kubevirt-manager
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubevirt-manager
namespace: kubevirt-manager
spec:
replicas: 1
selector:
matchLabels:
app: kubevirt-manager
template:
metadata:
labels:
app: kubevirt-manager
spec:
serviceAccountName: kubevirt-manager
containers:
- name: app
image: kubevirtmanager/kubevirt-manager:latest
ports: [{containerPort: 8080}]
resources:
requests:
cpu: 20m
memory: 64Mi
limits:
memory: 256Mi
---
apiVersion: v1
kind: Service
metadata:
name: kubevirt-manager
namespace: kubevirt-manager
spec:
type: LoadBalancer
loadBalancerIP: 10.10.200.62
selector:
app: kubevirt-manager
ports:
- port: 80
targetPort: 8080
EOF
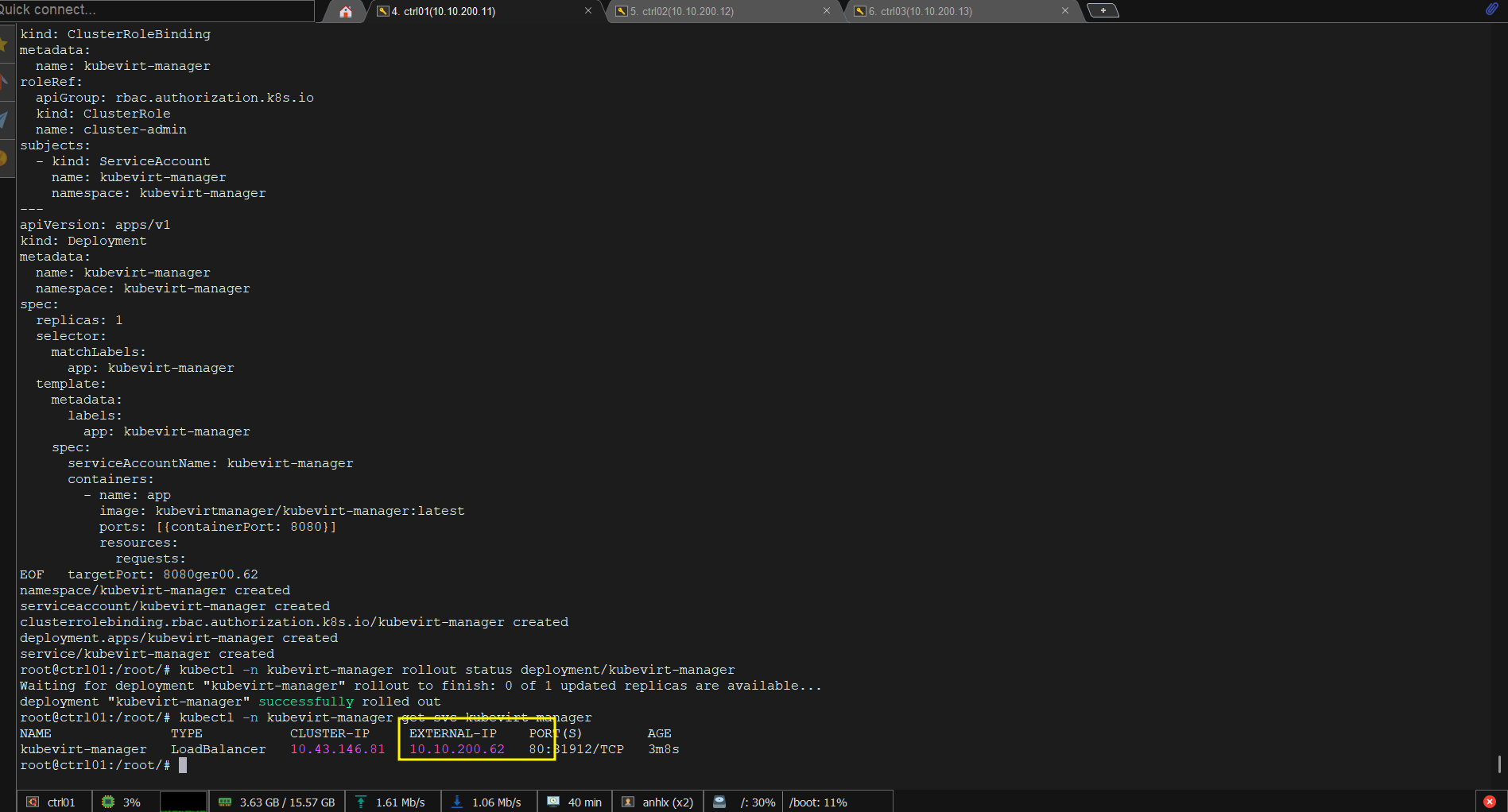
kubectl -n kubevirt-manager rollout status deployment/kubevirt-manager
# Lấy endpoint kubevirt-manager dashboard
kubectl -n kubevirt-manager get svc kubevirt-manager
Truy cập http://10.10.200.62 — admin có thể list VM, start/stop/restart, mở VNC console, trigger live migration.
Lưu ý: KubeVirt Manager không có built-in authentication. Production nên đặt sau ingress với OAuth2 Proxy (e.g., oauth2-proxy + Keycloak) hoặc basic auth. Lab này chỉ expose trong VLAN nội bộ nên không cần.
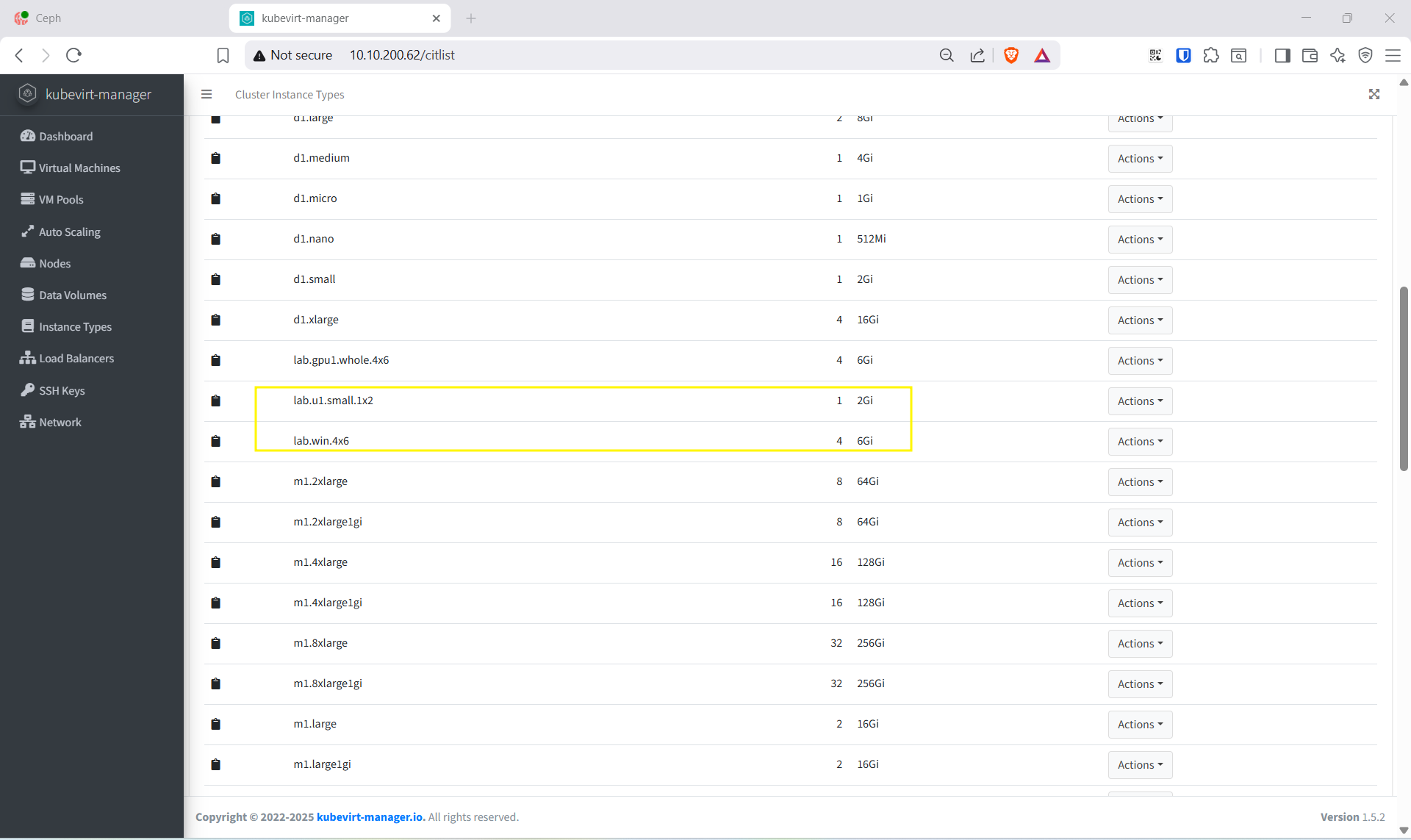
VM size catalog — admin dùng khi provision VM cho KH3 Ubuntu (lab.u1.small.1x2) và KH3 Windows (lab.win.4x6):
kubectl apply -f - <<EOF
---
apiVersion: instancetype.kubevirt.io/v1beta1
kind: VirtualMachineClusterInstancetype
metadata:
name: lab.u1.small.1x2
spec:
cpu:
guest: 1
memory:
guest: 2Gi
---
apiVersion: instancetype.kubevirt.io/v1beta1
kind: VirtualMachineClusterInstancetype
metadata:
name: lab.gpu1.whole.4x6
spec:
cpu:
guest: 4
memory:
guest: 6Gi
gpus:
- name: gpu1
deviceName: nvidia.com/gpu
---
apiVersion: instancetype.kubevirt.io/v1beta1
kind: VirtualMachineClusterInstancetype
metadata:
name: lab.win.4x6
spec:
cpu:
guest: 4
memory:
guest: 6Gi
---
apiVersion: instancetype.kubevirt.io/v1beta1
kind: VirtualMachineClusterPreference
metadata:
name: ubuntu
spec:
cpu:
preferredCPUTopology: preferSockets
devices:
preferredDiskBus: virtio
preferredInterfaceModel: virtio
features:
preferredAcpi: {}
firmware:
preferredUseEfi: true
---
apiVersion: instancetype.kubevirt.io/v1beta1
kind: VirtualMachineClusterPreference
metadata:
name: windows.2k22
spec:
clock:
preferredClockOffset:
timezone: "Asia/Ho_Chi_Minh"
preferredTimer:
hpet:
present: false
hyperv: {}
pit:
tickPolicy: delay
rtc:
tickPolicy: catchup
cpu:
preferredCPUTopology: preferSockets
devices:
preferredDiskBus: sata
preferredInterfaceModel: e1000
preferredTPM: {}
features:
preferredAcpi: {}
preferredApic: {}
preferredHyperv:
relaxed: {}
vapic: {}
spinlocks:
spinlocks: 8191
preferredSmm: {}
firmware:
preferredUseEfi: true
preferredEfi:
secureBoot: false
EOF
8. fake-gpu-operator — GPU Topology
Mình phân bổ 3 node theo loại GPU pool:
- ctrl01 — pool
whole, 2 GPU integer (không time-slicing) - ctrl02 — pool
shared, 2 GPU × 4 slice = 8 fractional - ctrl03 — KHÔNG có GPU pool, không label fake-gpu-operator
Bước 1: cài KWOK (dependency của fake-gpu-operator):
KWOK_VERSION=v0.7.0
kubectl apply -f https://github.com/kubernetes-sigs/kwok/releases/download/${KWOK_VERSION}/kwok.yaml
kubectl -n kube-system get pods -l app=kwok-controller
# kwok-controller-xxxxx 1/1 Running
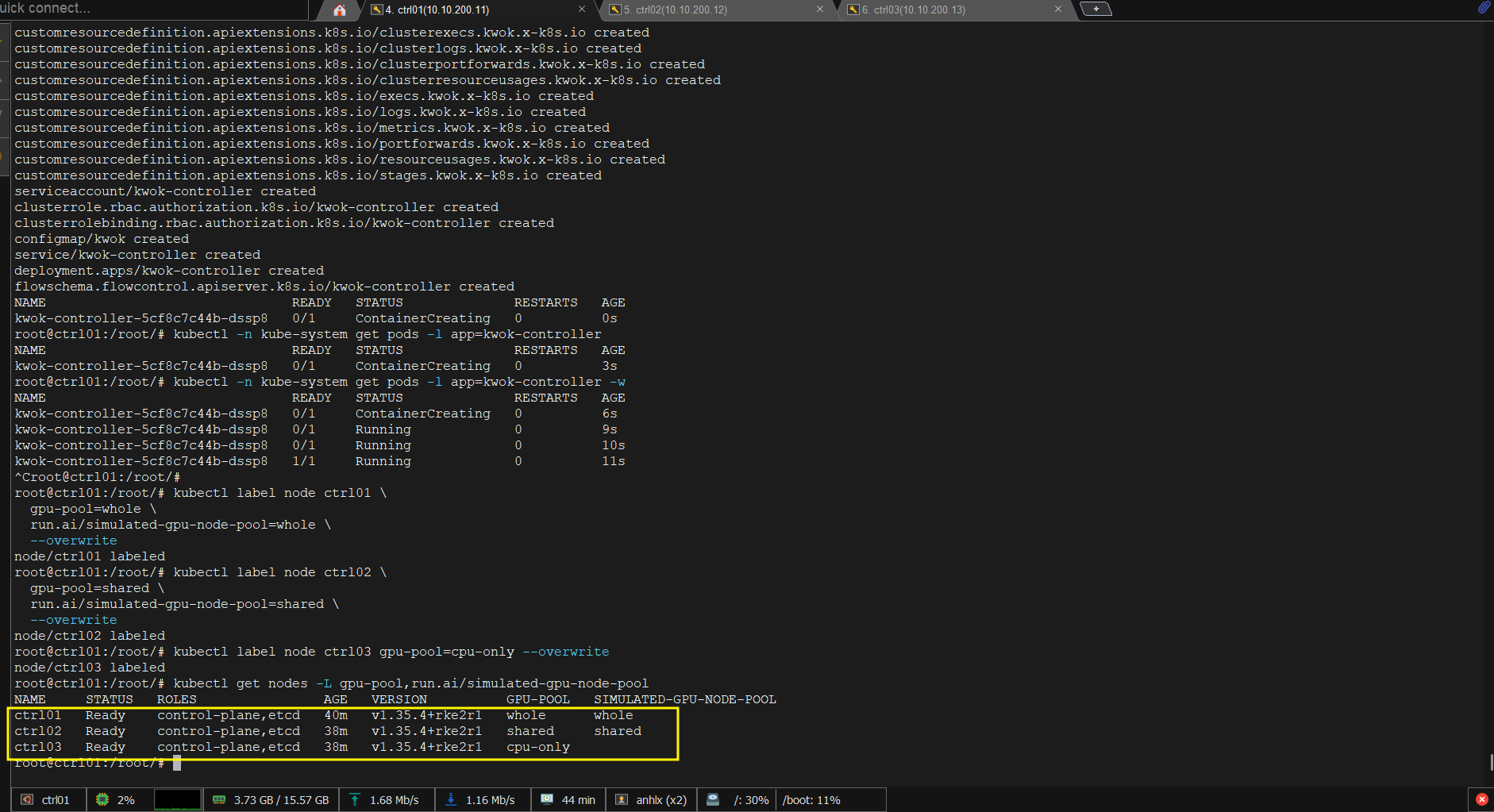
Bước 2: Label nodes — đây là cách phân bổ chính:
kubectl label node ctrl01 \
gpu-pool=whole \
run.ai/simulated-gpu-node-pool=whole \
--overwrite
kubectl label node ctrl02 \
gpu-pool=shared \
run.ai/simulated-gpu-node-pool=shared \
--overwrite
kubectl label node ctrl03 gpu-pool=cpu-only --overwrite
kubectl get nodes -L gpu-pool,run.ai/simulated-gpu-node-pool
Bước 3: cài fake-gpu-operator với 2 node pool (whole + shared):
kubectl delete runtimeclass nvidia --ignore-not-found
helm upgrade -i gpu-operator \
oci://ghcr.io/run-ai/fake-gpu-operator/fake-gpu-operator \
-n gpu-operator --create-namespace \
--set 'topology.nodePools.whole.gpuCount=2' \
--set 'topology.nodePools.whole.gpuProduct=NVIDIA-A100-SXM4-40GB' \
--set 'topology.nodePools.shared.gpuCount=2' \
--set 'topology.nodePools.shared.gpuProduct=NVIDIA-A100-SXM4-40GB'
kubectl -n gpu-operator get pods -o wide
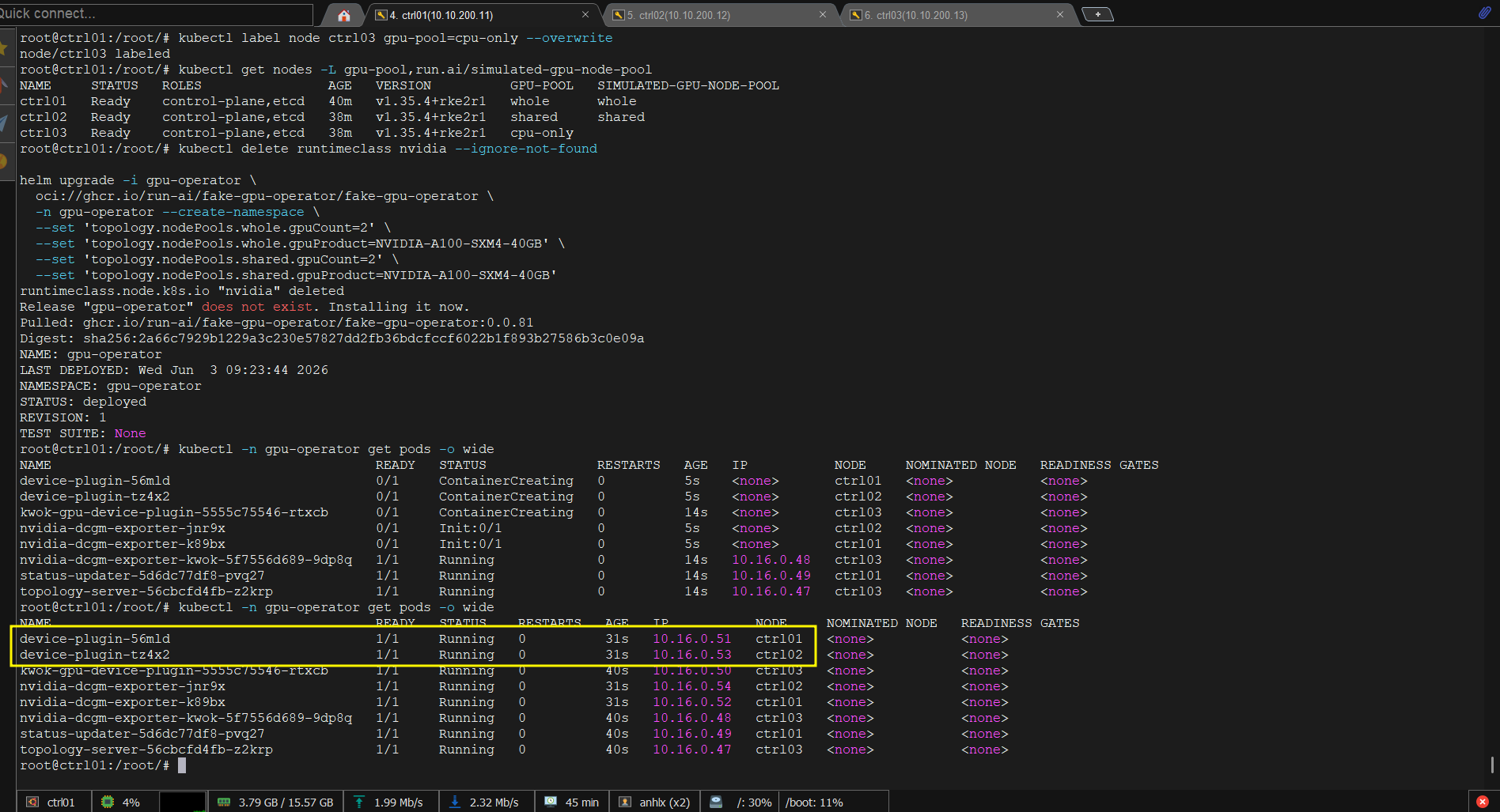
Bước 4: configure time-slicing cho pool shared:
helm upgrade gpu-operator \
oci://ghcr.io/run-ai/fake-gpu-operator/fake-gpu-operator \
--namespace gpu-operator \
--set topology.nodePools.whole.gpuCount=2 \
--set topology.nodePools.whole.gpuProduct=NVIDIA-A100-SXM4-40GB \
--set topology.nodePools.shared.gpuCount=8 \
--set topology.nodePools.shared.gpuProduct=NVIDIA-A100-SXM4-40GB \
--set topology.nodePools.shared.replicasPerGpu=4 \
--wait
kubectl -n gpu-operator delete configmap topology-ctrl02
kubectl -n gpu-operator rollout restart deployment/status-updater
sleep 15
kubectl -n gpu-operator delete pod -l app=device-plugin --field-selector spec.nodeName=ctrl02
sleep 15
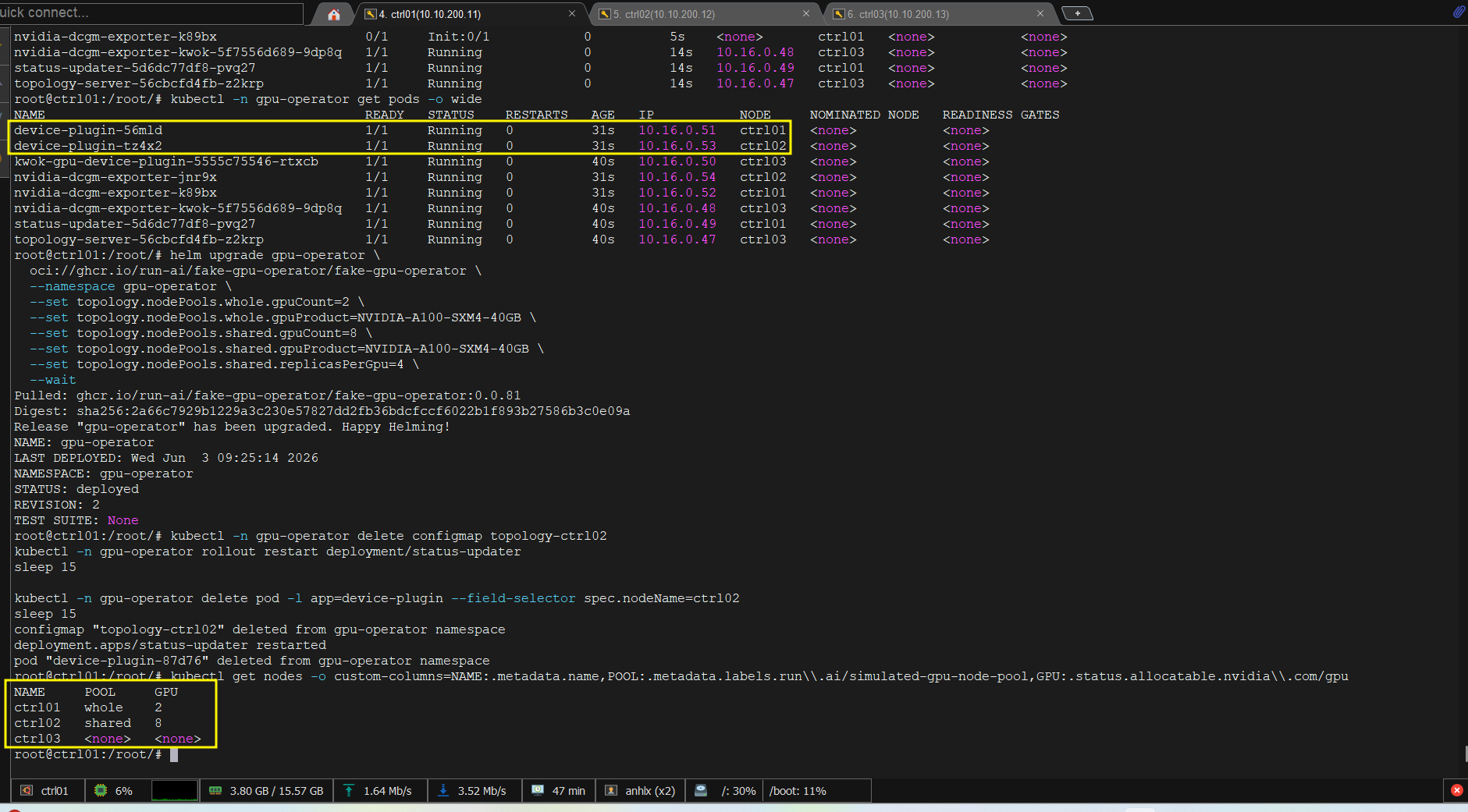
Bước 5: verify GPU advertised đúng:
kubectl get nodes -o custom-columns=NAME:.metadata.name,POOL:.metadata.labels.run\\.ai/simulated-gpu-node-pool,GPU:.status.allocatable.nvidia\\.com/gpu
# NAME POOL GPU
# ctrl01 whole 2
# ctrl02 shared 8
# ctrl03 <none> <none>
9. Capsule — Multi-tenancy
Capsule enforce multi-tenancy đúng nghĩa khi tenant SA không được cấp cluster-admin. Custom ClusterRole tenant-owner với verbs giới hạn là cách đúng — Capsule tự generate RoleBinding trong namespace của tenant.
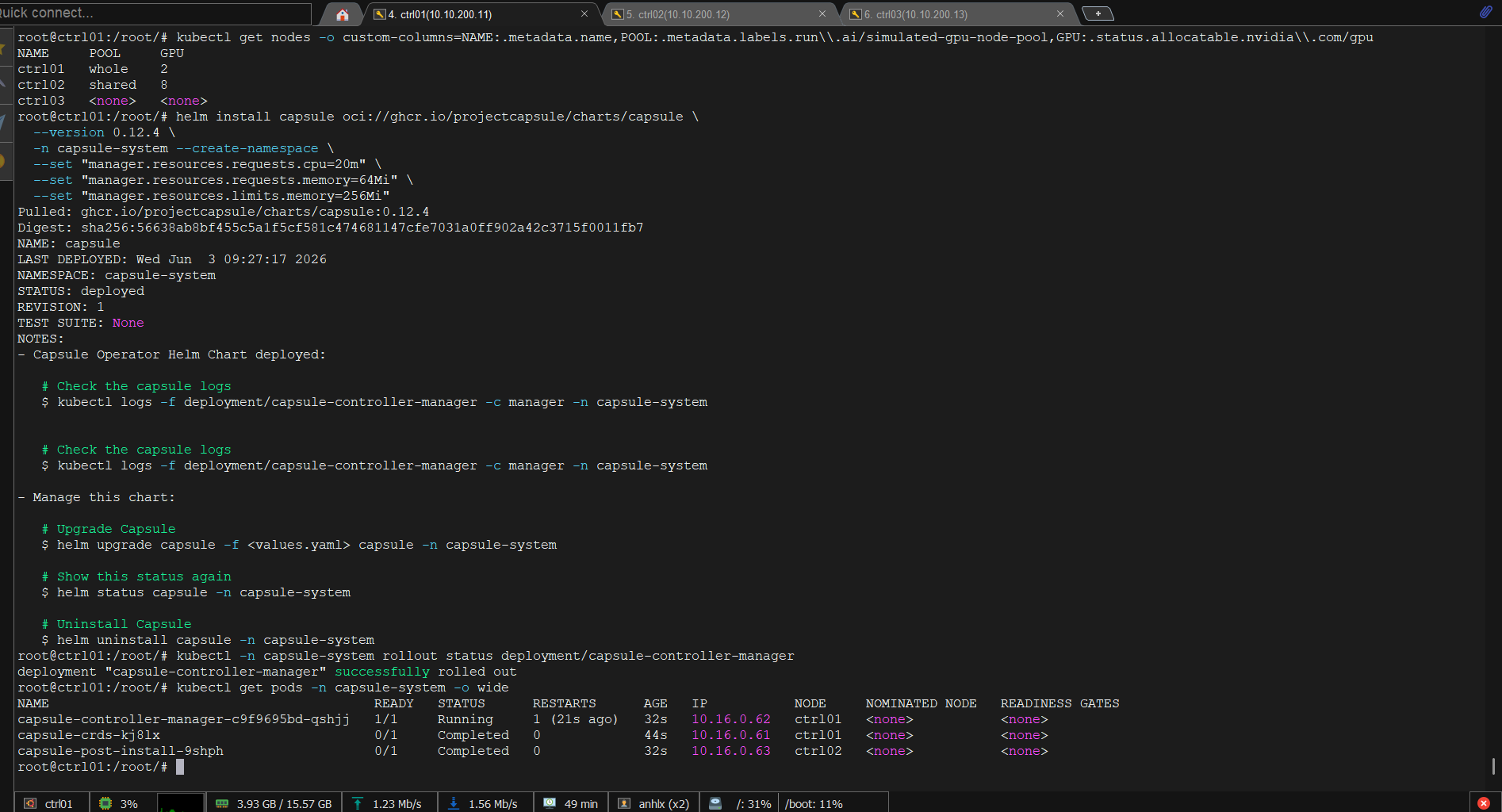
9.1 Cài Capsule
helm install capsule oci://ghcr.io/projectcapsule/charts/capsule \
--version 0.12.4 \
-n capsule-system --create-namespace \
--set "manager.resources.requests.cpu=20m" \
--set "manager.resources.requests.memory=64Mi" \
--set "manager.resources.limits.memory=256Mi"
kubectl -n capsule-system rollout status deployment/capsule-controller-manager
kubectl get pods -n capsule-system
# capsule-controller-manager-xxxxx 1/1 Running
9.2 Tạo custom ClusterRole tenant-owner
kubectl apply -f - <<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: tenant-owner
labels:
capsule.clastix.io/aggregation-to-tenant-owner: "true"
rules:
- apiGroups: [""]
resources:
- pods
- pods/log
- pods/exec
- pods/portforward
- pods/attach
- services
- configmaps
- secrets
- persistentvolumeclaims
- events
- serviceaccounts
verbs: ["get","list","watch","create","update","patch","delete"]
- apiGroups: [""]
resources: ["namespaces"]
verbs: ["get","list","watch","create","update","patch","delete"]
- apiGroups: ["apps"]
resources: ["deployments","statefulsets","daemonsets","replicasets"]
verbs: ["get","list","watch","create","update","patch","delete"]
- apiGroups: ["batch"]
resources: ["jobs","cronjobs"]
verbs: ["get","list","watch","create","update","patch","delete"]
- apiGroups: ["kubevirt.io"]
resources:
- virtualmachines
- virtualmachineinstances
- virtualmachineinstancemigrations
verbs: ["get","list","watch","create","update","patch","delete"]
- apiGroups: ["subresources.kubevirt.io"]
resources:
- virtualmachineinstances/console
- virtualmachineinstances/vnc
- virtualmachines/start
- virtualmachines/stop
- virtualmachines/restart
- virtualmachines/migrate
verbs: ["get","update"]
- apiGroups: ["cdi.kubevirt.io"]
resources: ["datavolumes","dataimportcrons","datasources"]
verbs: ["get","list","watch","create","update","patch","delete"]
- apiGroups: ["networking.k8s.io"]
resources: ["networkpolicies","ingresses"]
verbs: ["get","list","watch","create","update","patch","delete"]
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get","list","watch"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses","volumesnapshotclasses"]
verbs: ["get","list","watch"]
- apiGroups: ["capsule.clastix.io"]
resources: ["tenants"]
verbs: ["get","list","watch"]
EOF
9.3 Helper script — sinh Capsule Tenant + kubeconfig
Script tạo Capsule Tenant, namespace, SA và kubeconfig. VPC/Network của từng tenant được tạo riêng ở bước đầu của mỗi khách hàng (section 11).
cat > ~/create-tenant.sh <<'SCRIPT'
#!/usr/bin/env bash
# Usage: ./create-tenant.sh <tenant-name> <gpu-pool> <gpu-quota> <vm-quota>
# gpu-pool="none" → tenant không bị giới hạn node, workload tự chọn qua nodeSelector
# Ví dụ: ./create-tenant.sh cust-cpu none 1 1
set -euo pipefail
TENANT_NAME="$1"
GPU_POOL="$2"
GPU_QUOTA="${3:-0}"
VM_QUOTA="${4:-1}"
NS="${TENANT_NAME}"
SA="${TENANT_NAME}-owner"
SERVER="https://10.10.200.51:6443"
# nodeSelector — bỏ qua khi GPU_POOL="none"
if [ "${GPU_POOL}" != "none" ]; then
NS_SELECTOR=" nodeSelector:
gpu-pool: \"${GPU_POOL}\""
else
NS_SELECTOR=""
fi
# Tạo Tenant CR
cat <<EOF | kubectl apply -f -
apiVersion: capsule.clastix.io/v1beta2
kind: Tenant
metadata:
name: ${TENANT_NAME}
spec:
owners:
- name: system:serviceaccount:${NS}:${SA}
kind: ServiceAccount
clusterRoles:
- tenant-owner
namespaceOptions:
quota: 1
${NS_SELECTOR}
storageClasses:
allowed:
- "rook-ceph-block"
- "rook-ceph-block-rwx"
- "rook-cephfs"
resourceQuotas:
scope: Tenant
items:
- hard:
requests.cpu: "4"
requests.memory: "8Gi"
limits.cpu: "6"
limits.memory: "10Gi"
requests.nvidia.com/gpu: "${GPU_QUOTA}"
limits.nvidia.com/gpu: "${GPU_QUOTA}"
persistentvolumeclaims: "5"
requests.storage: "100Gi"
count/virtualmachines.kubevirt.io: "${VM_QUOTA}"
EOF
# Namespace + labels (idempotent)
kubectl create namespace "${NS}" --dry-run=client -o yaml | kubectl apply -f -
kubectl label namespace "${NS}" "capsule.clastix.io/tenant=${TENANT_NAME}" --overwrite
# ServiceAccount
kubectl create serviceaccount "${SA}" -n "${NS}" --dry-run=client -o yaml | kubectl apply -f -
# RoleBinding manual (namespace tạo bởi admin bypass Capsule webhook)
kubectl apply -f - <<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: capsule-${TENANT_NAME}-0
namespace: ${NS}
labels:
capsule.clastix.io/tenant: "${TENANT_NAME}"
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: tenant-owner
subjects:
- kind: ServiceAccount
name: ${SA}
namespace: ${NS}
EOF
# SA token
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Secret
metadata:
name: ${SA}-token
namespace: ${NS}
annotations:
kubernetes.io/service-account.name: ${SA}
type: kubernetes.io/service-account-token
EOF
sleep 5
TOKEN=$(kubectl -n "${NS}" get secret "${SA}-token" -o jsonpath='{.data.token}' | base64 -d)
CA=$(kubectl -n "${NS}" get secret "${SA}-token" -o jsonpath='{.data.ca\.crt}')
# Sinh kubeconfig
mkdir -p ~/kubeconfigs
cat > ~/kubeconfigs/${TENANT_NAME}.kubeconfig <<EOF
apiVersion: v1
kind: Config
clusters:
- name: lab-cluster
cluster:
server: ${SERVER}
certificate-authority-data: ${CA}
users:
- name: ${SA}
user:
token: ${TOKEN}
contexts:
- name: ${TENANT_NAME}
context:
cluster: lab-cluster
namespace: ${NS}
user: ${SA}
current-context: ${TENANT_NAME}
EOF
echo "===================================="
echo "Tenant ${TENANT_NAME} created"
echo " Namespace : ${NS}"
echo " GPU pool : ${GPU_POOL} | GPU quota: ${GPU_QUOTA} | VM quota: ${VM_QUOTA}"
echo " Kubeconfig: ~/kubeconfigs/${TENANT_NAME}.kubeconfig"
echo " Token : ${TOKEN}"
echo "===================================="
SCRIPT
chmod +x ~/create-tenant.sh
10. Golden Image Templates
Mình chuẩn bị golden image một lần — khi có KH mới, admin clone PVC ra là xong, không cài lại OS hay pull image từ đầu.
kubectl create namespace vm-images
10.1 Ubuntu 22.04 — VM golden image
wget --progress=bar:force https://cloud-images.ubuntu.com/jammy/current/jammy-server-cloudimg-amd64.img \
-O /tmp/jammy.img
python3 -m http.server 8888 --directory /tmp &
kubectl apply -f - <<EOF
apiVersion: cdi.kubevirt.io/v1beta1
kind: DataVolume
metadata:
name: ubuntu-2204-golden
namespace: vm-images
spec:
source:
http:
url: "http://10.10.200.11:8888/jammy.img"
storage:
accessModes: [ReadWriteMany]
volumeMode: Filesystem
resources:
requests:
storage: 10Gi
storageClassName: rook-cephfs
EOF
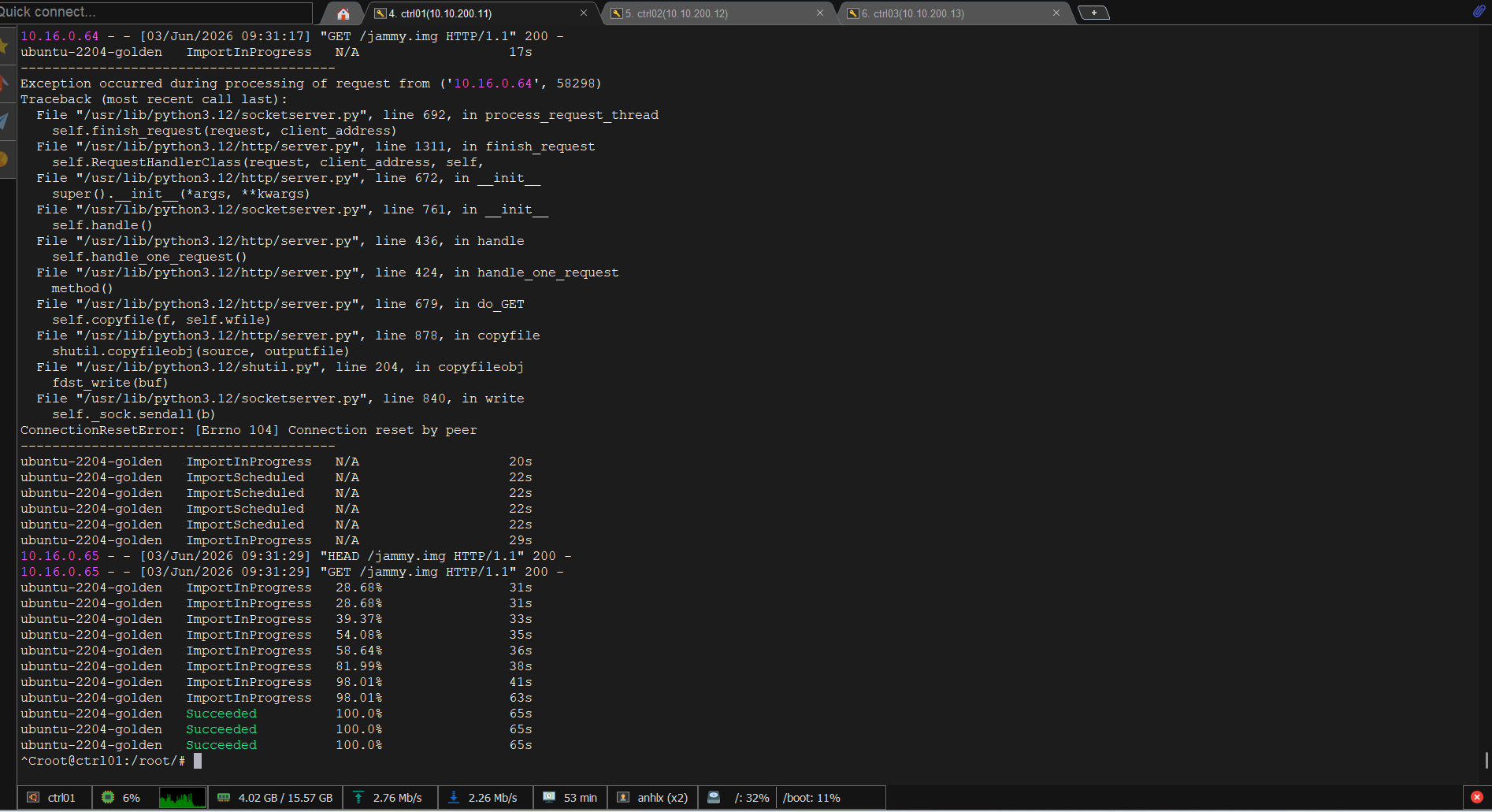
kubectl get dv ubuntu-2204-golden -n vm-images -w
# NAME PHASE PROGRESS
# ubuntu-2204-golden Succeeded 100.0%
10.2 Windows Server 2022 — VM golden image
Mình SCP Windows ISO từ máy local lên ctrl01 rồi import vào vm-images.
python3 -m http.server 8888 --directory /tmp &
kubectl apply -f - <<EOF
apiVersion: cdi.kubevirt.io/v1beta1
kind: DataVolume
metadata:
name: windows-2022-iso
namespace: vm-images
spec:
source:
http:
url: "http://10.10.200.11:8888/win2022.iso"
storage:
accessModes: [ReadWriteOnce]
volumeMode: Filesystem
resources:
requests:
storage: 6Gi
storageClassName: rook-ceph-block
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: windows-2022-golden
namespace: vm-images
spec:
accessModes: [ReadWriteMany]
storageClassName: rook-ceph-block-rwx
volumeMode: Block
resources:
requests:
storage: 60Gi
EOF
Tạo VM installer để cài Windows:
kubectl apply -f - <<EOF
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: windows-installer
namespace: vm-images
spec:
runStrategy: Manual
template:
spec:
nodeSelector:
gpu-pool: cpu-only
domain:
cpu:
cores: 4
sockets: 1
threads: 1
memory:
guest: 6Gi
firmware:
bootloader:
efi:
secureBoot: false
clock:
timezone: "Asia/Ho_Chi_Minh"
timer:
hpet:
present: false
hyperv: {}
pit:
tickPolicy: delay
rtc:
tickPolicy: catchup
features:
acpi: {}
apic: {}
smm:
enabled: true
hyperv:
relaxed: {}
vapic: {}
spinlocks:
spinlocks: 8191
devices:
tpm: {}
disks:
- name: rootdisk
disk:
bus: virtio
bootOrder: 2
- name: installer-iso
cdrom:
bus: sata
bootOrder: 1
- name: virtiocontainerdisk
cdrom:
bus: sata
bootOrder: 3
interfaces:
- name: default
masquerade: {}
model: e1000
networks:
- name: default
pod: {}
volumes:
- name: rootdisk
persistentVolumeClaim:
claimName: windows-2022-golden
- name: installer-iso
persistentVolumeClaim:
claimName: windows-2022-iso
- name: virtiocontainerdisk
containerDisk:
image: quay.io/kubevirt/virtio-container-disk:v1.8.0
EOF
virtctl start windows-installer -n vm-images
Mở VNC console để cài Windows (VNC → 10.10.200.11:5900):
virtctl vnc windows-installer -n vm-images --proxy-only --port=5900 --address=0.0.0.0
Trong installer:
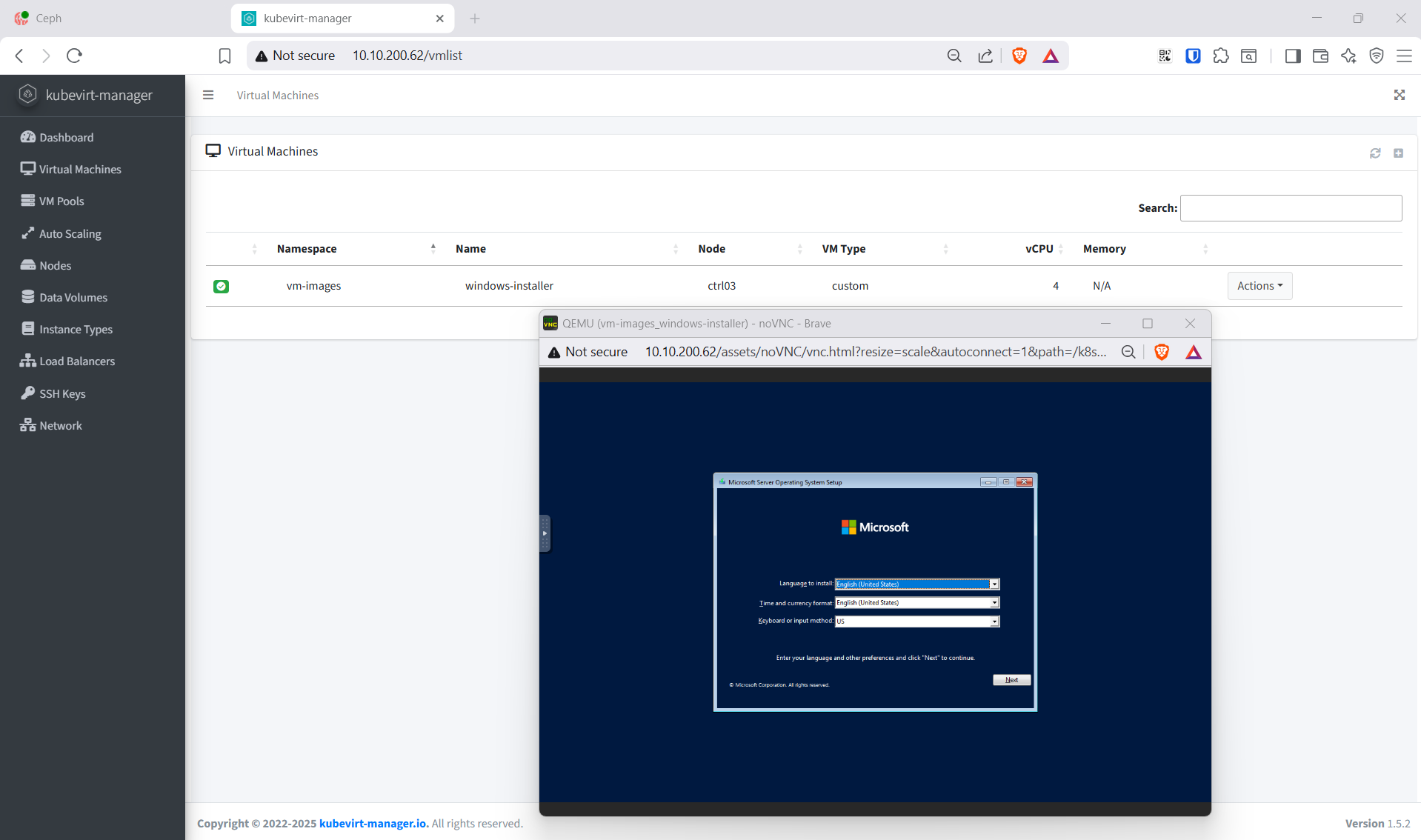
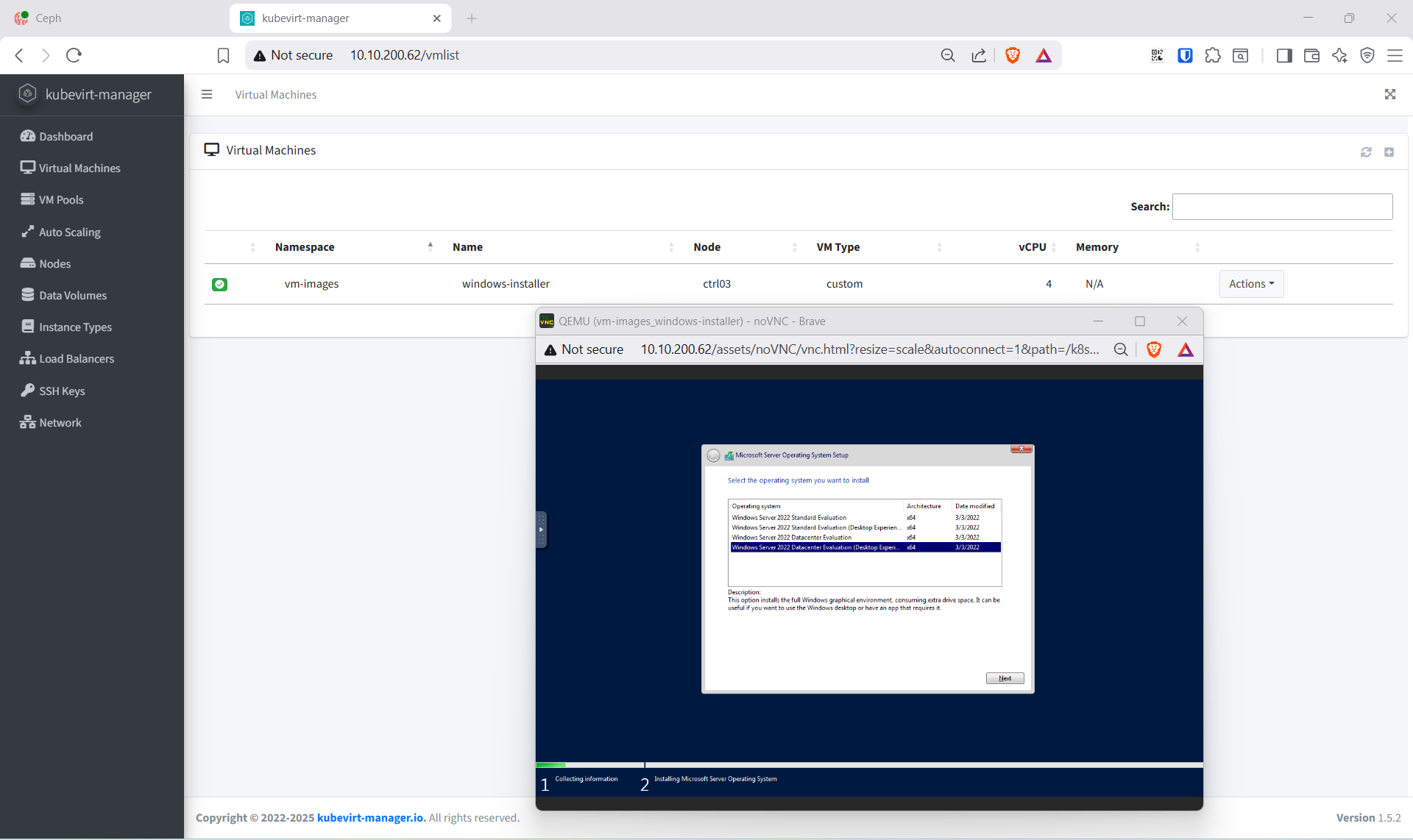
- Boot từ DVD → ngôn ngữ → edition Standard Desktop Experience
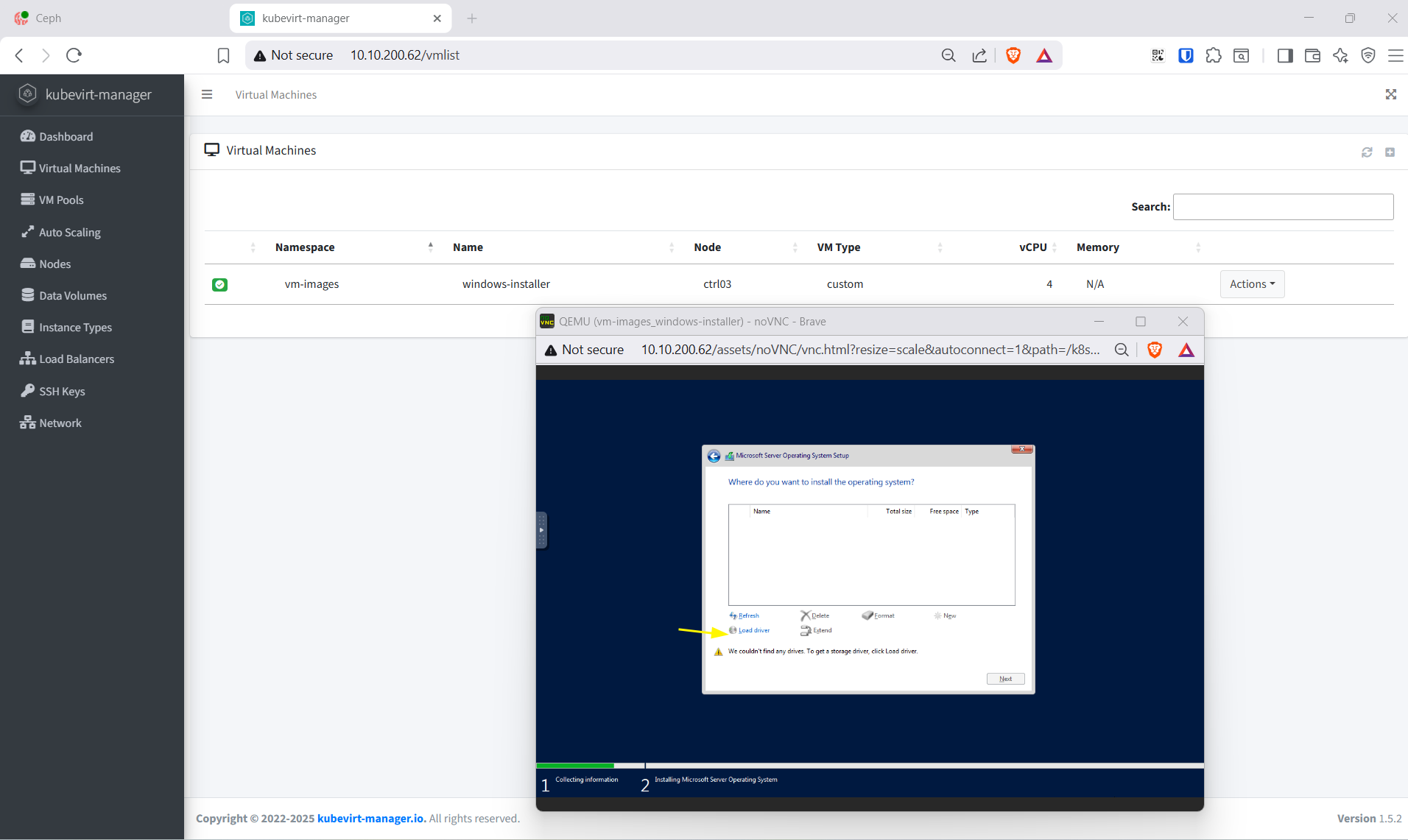
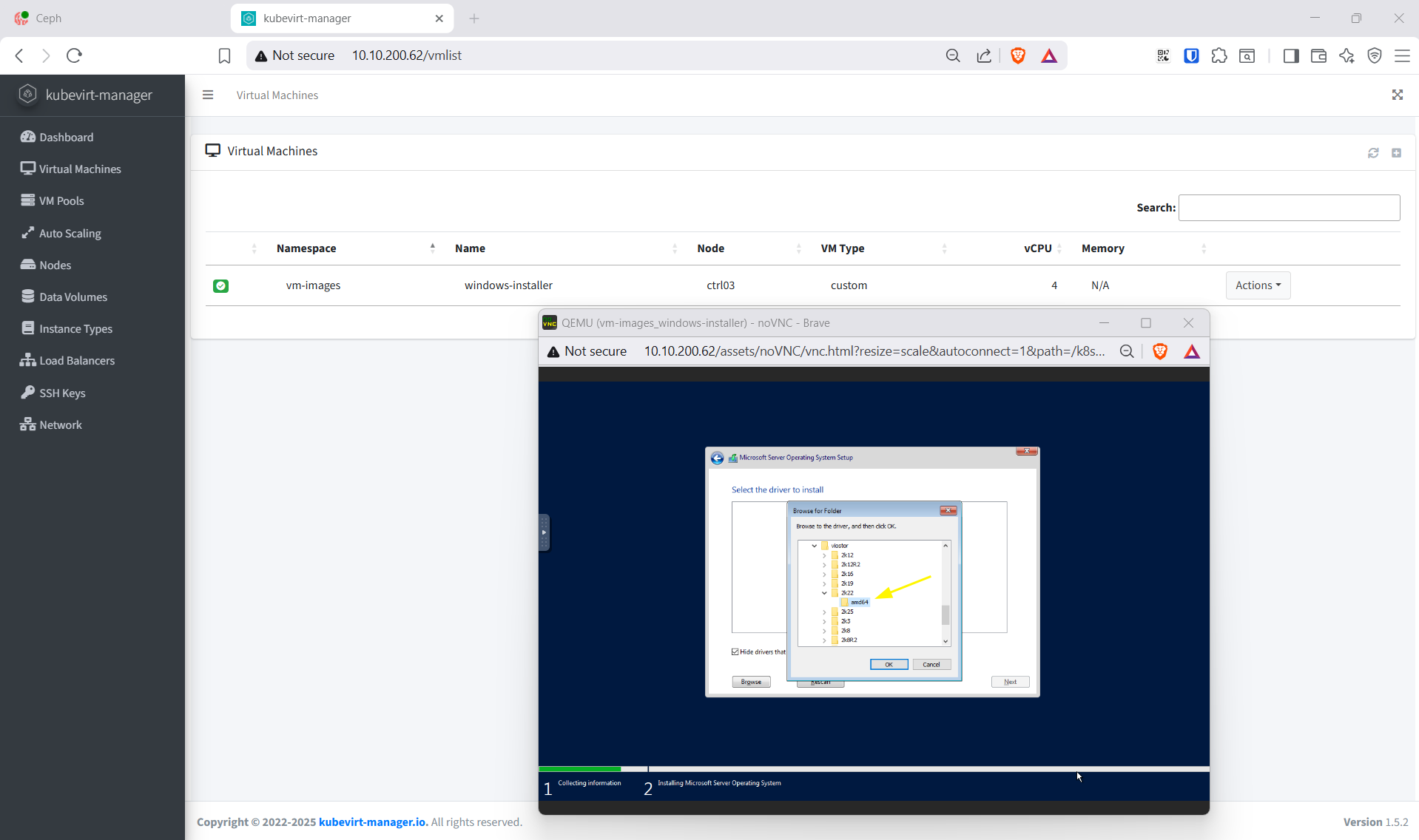
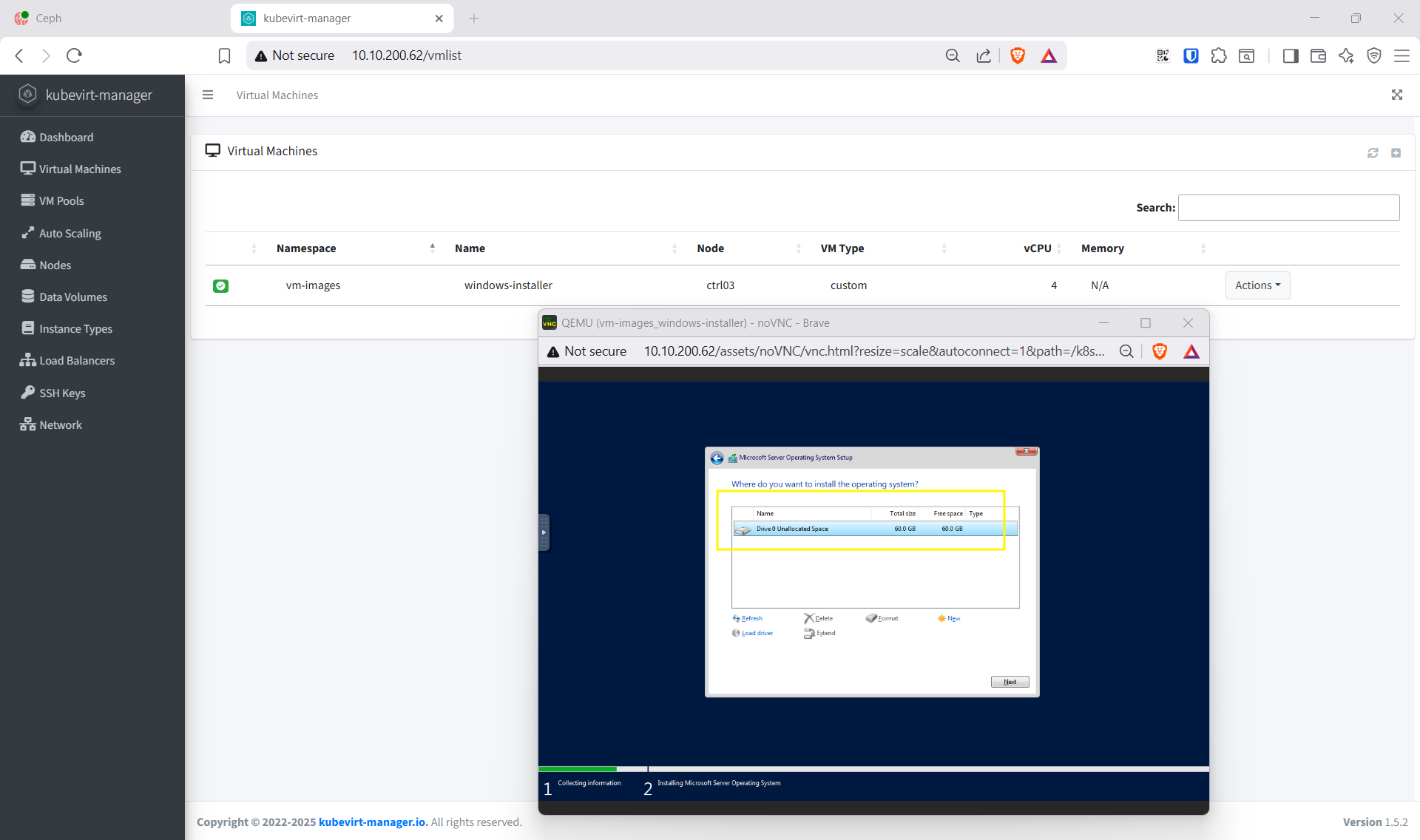
- Custom install → Load driver →
viostor\2k22\amd64→ install → disk 60 GB hiện ra → Next → Install - Reboot → tạo Administrator password → login desktop
- Mount virtio-win CD →
virtio-win-gt-x64.msi→ install tất cả driver → reboot
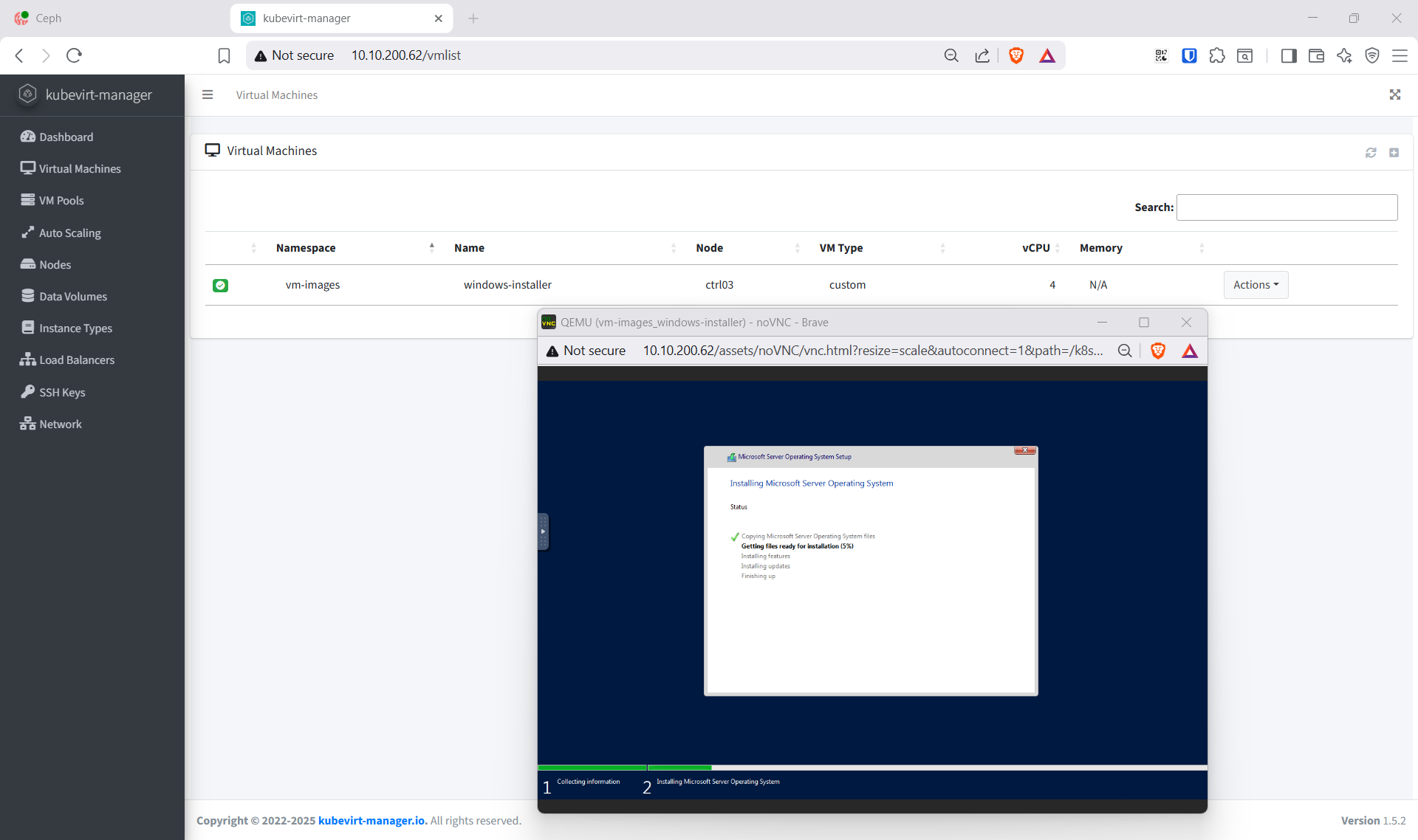
Bật RDP rồi chạy sysprep để hoàn tất golden image:
Set-ItemProperty -Path 'HKLM:\System\CurrentControlSet\Control\Terminal Server' -Name "fDenyTSConnections" -Value 0
Enable-NetFirewallRule -DisplayGroup "Remote Desktop"
Restart-Service -Name TermService -Force
C:\Windows\System32\Sysprep\sysprep.exe /generalize /oobe /shutdown
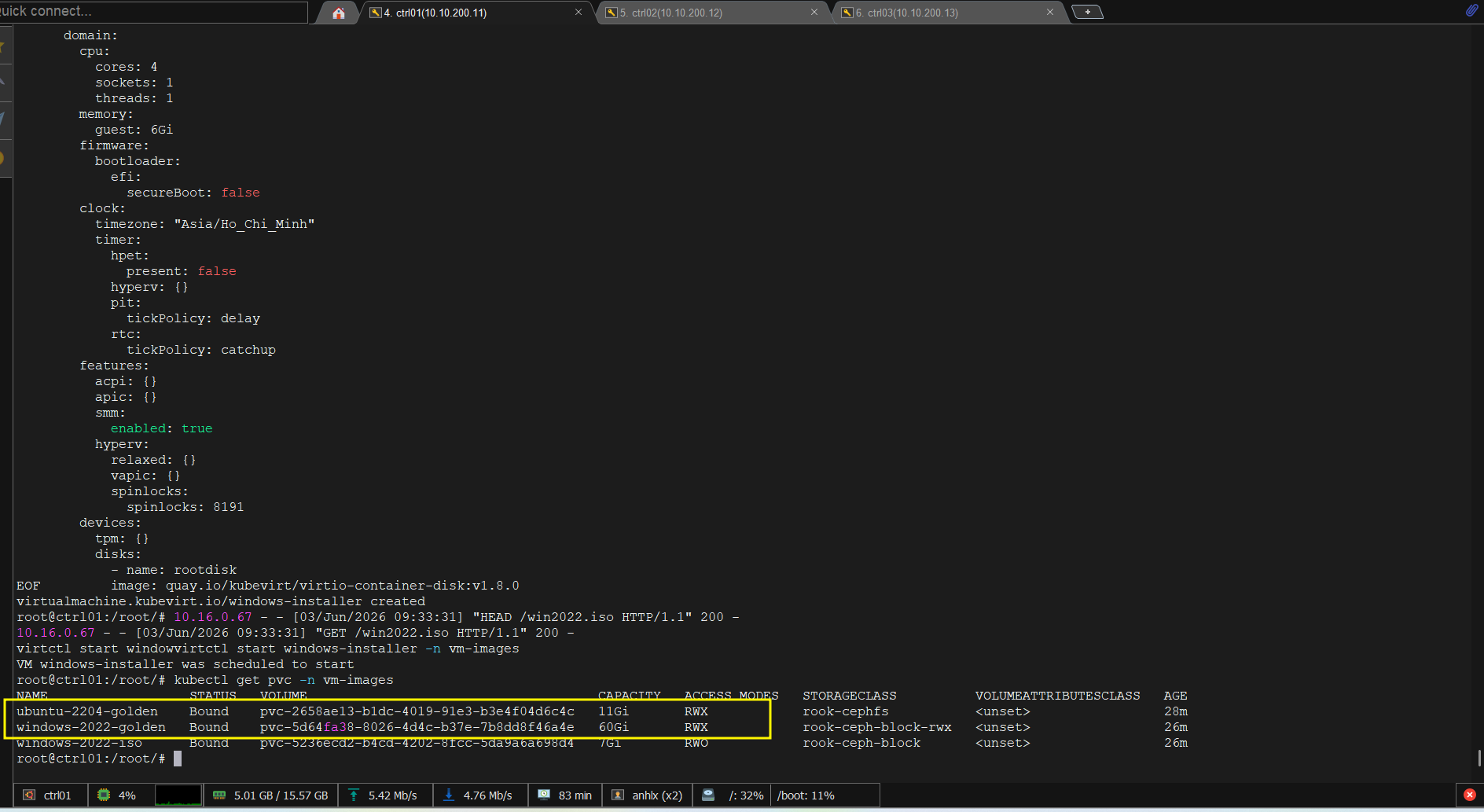
Sau khi VMI chuyển sang phase Succeeded:
kubectl get pvc -n vm-images windows-2022-golden
kubectl delete vm windows-installer -n vm-images
kubectl delete dv windows-2022-iso -n vm-images
Hoặc cài Windows qua Web Ui KubeVirt Manager
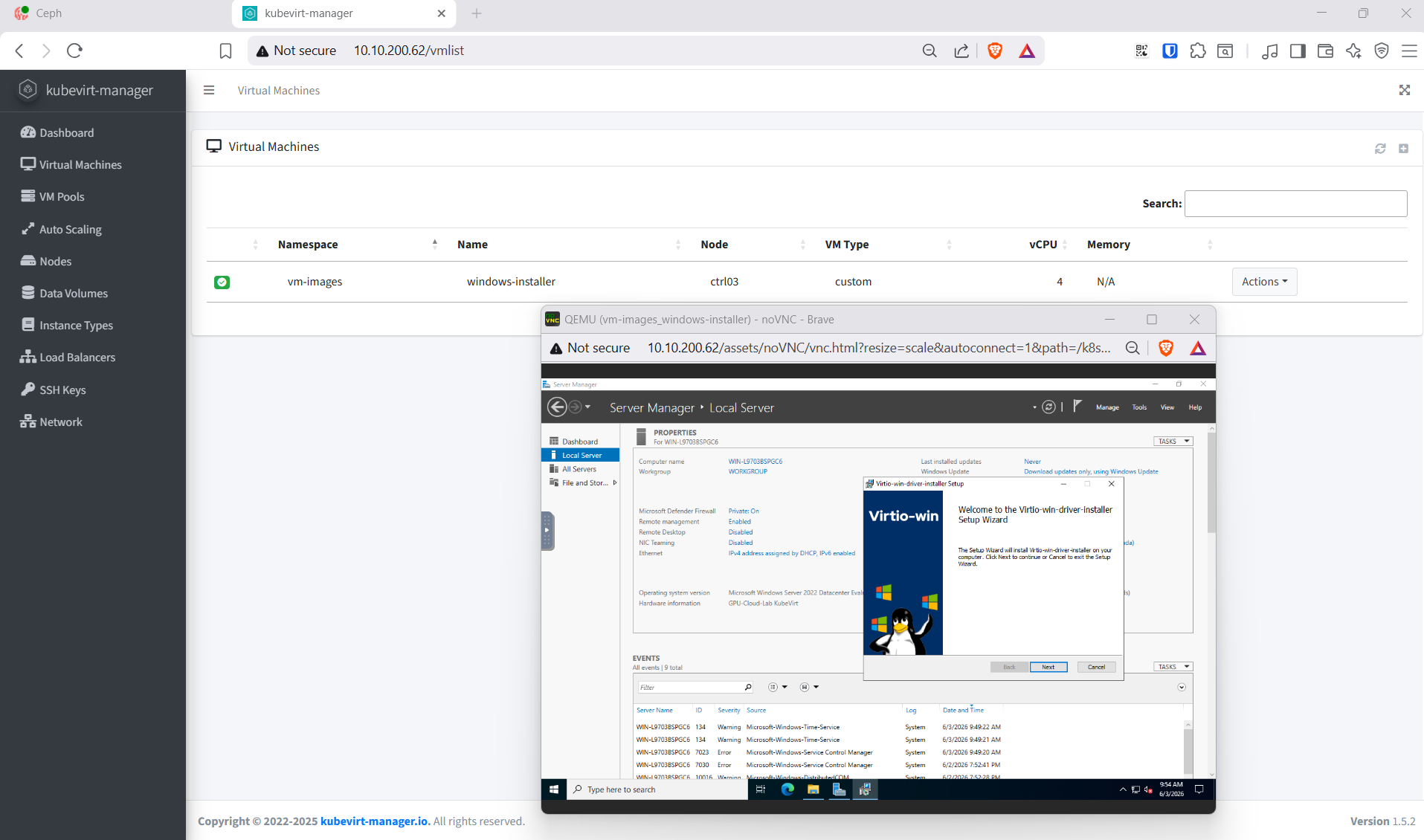
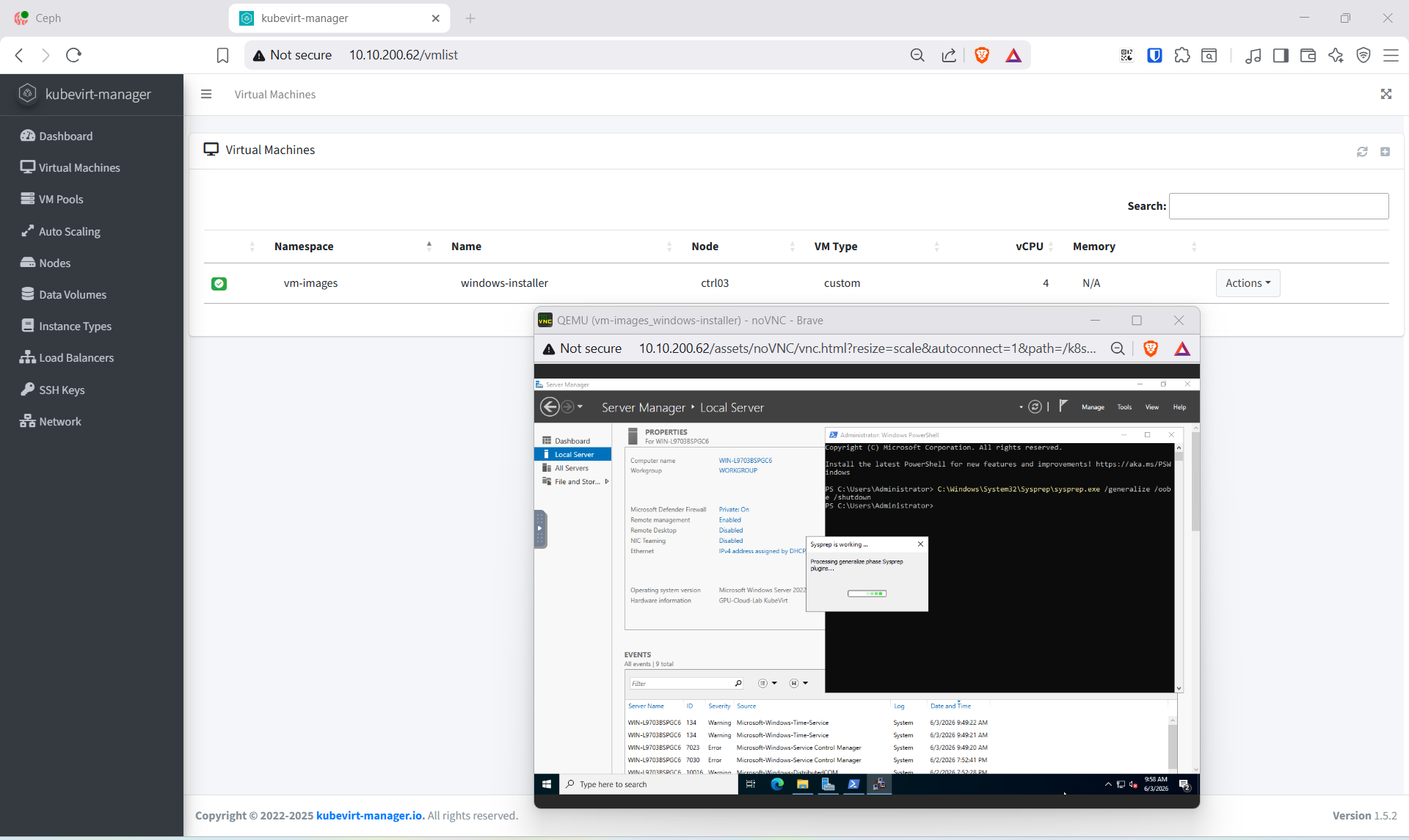
10.3 Container template — CUDA workload
Mình lưu sẵn manifest CUDA container vào ConfigMap để admin tái dùng cho các tenant GPU shared:
kubectl apply -f - <<EOF
apiVersion: v1
kind: ConfigMap
metadata:
name: cuda-container-template
namespace: vm-images
data:
template.yaml: |
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: TENANT-data
namespace: TENANT-NAMESPACE
spec:
accessModes: [ReadWriteOnce]
storageClassName: rook-ceph-block
resources:
requests:
storage: 10Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: TENANT-gpu-app
namespace: TENANT-NAMESPACE
spec:
replicas: 1
selector:
matchLabels:
app: TENANT-gpu-app
template:
metadata:
labels:
app: TENANT-gpu-app
spec:
dnsPolicy: None
dnsConfig:
nameservers:
- 8.8.8.8
containers:
- name: cuda
image: nvcr.io/nvidia/cuda:12.6.0-base-ubuntu22.04
command: ["sh", "-c"]
args:
- |
apt-get update -qq && apt-get install -qq -y openssh-server > /dev/null 2>&1
mkdir -p /run/sshd
echo 'root:PASSWD' | chpasswd
sed -i 's/#PermitRootLogin .*/PermitRootLogin yes/' /etc/ssh/sshd_config
sed -i 's/#PasswordAuthentication.*/PasswordAuthentication yes/' /etc/ssh/sshd_config
/usr/sbin/sshd -D
resources:
requests:
cpu: 500m
memory: 1Gi
nvidia.com/gpu: 1
limits:
cpu: 2
memory: 2Gi
nvidia.com/gpu: 1
ports:
- containerPort: 22
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
persistentVolumeClaim:
claimName: TENANT-data
EOF
11. Demo: Onboard 3 Khách Hàng
Đây là phần demo flow thật sự của GPU cloud — cách admin onboard một khách hàng mới vào cluster. Mỗi khách hàng trải qua 3 bước theo thứ tự:
- Tạo mạng riêng — VPC + Subnet + NAT Gateway + EIP + NAD (nếu cần VM)
- Tạo tenant — Capsule Tenant + kubeconfig để KH tự deploy
- Provision workload — clone golden image, deploy VM hoặc container
11.1 Tổng quan 3 khách hàng
| KH | Tenant | Sản phẩm | Node | VPC Subnet | Floating IP |
|---|---|---|---|---|---|
| KH1 | cust-gpu-whole |
Container CUDA 1 GPU nguyên | ctrl01 | 192.168.10.0/24 | .71:22 SSH |
| KH2 | cust-gpu-shared |
Container CUDA 2 GPU chia nhỏ | ctrl02 | 192.168.20.0/24 | .72:22 SSH |
| KH3 | cust-cpu |
VM Ubuntu 22.04 + VM Windows Server 2022 (không GPU) | ctrl03 | 192.168.30.0/24 | .73:22 SSH (Ubuntu) / .73:3389 RDP (Windows) |
11.2 KH1 — Container CUDA nguyên GPU
Khách hàng: AI startup cần nguyên GPU cho training model, không muốn chia sẻ GPU slice với workload khác.
11.2.1 Tạo VPC + Subnet + NAT Gateway + EIP
KH1 dùng container thuần — không cần Multus NAD. Kube-OVN gán VPC IP trực tiếp qua annotation vào namespace.
export KUBECONFIG=~/rke2.yaml
kubectl create namespace cust-gpu-whole
kubectl apply -f - <<EOF
# --- VPC ---
apiVersion: kubeovn.io/v1
kind: Vpc
metadata:
name: cust-gpu-whole-vpc
spec:
namespaces:
- cust-gpu-whole
---
# --- Subnet (namespace binding — pod tự nhận VPC IP) ---
apiVersion: kubeovn.io/v1
kind: Subnet
metadata:
name: cust-gpu-whole-subnet
spec:
vpc: cust-gpu-whole-vpc
protocol: IPv4
cidrBlock: 192.168.10.0/24
gateway: 192.168.10.254
excludeIps:
- 192.168.10.254
enableDHCP: true
namespaces:
- cust-gpu-whole
dhcpV4Options: "lease_time=3600,router=192.168.10.254,server_id=192.168.10.254,dns_server=8.8.8.8"
---
# --- NAT Gateway ---
apiVersion: kubeovn.io/v1
kind: VpcNatGateway
metadata:
name: cust-gpu-whole-natgw
spec:
vpc: cust-gpu-whole-vpc
subnet: cust-gpu-whole-subnet
lanIp: 192.168.10.254
selector:
- "kubernetes.io/os: linux"
tolerations:
- operator: Exists
---
# --- EIP + SNAT ---
apiVersion: kubeovn.io/v1
kind: IptablesEIP
metadata:
name: kh1-eip
spec:
v4ip: 10.10.200.71
natGwDp: cust-gpu-whole-natgw
---
apiVersion: kubeovn.io/v1
kind: IptablesSnatRule
metadata:
name: kh1-snat
spec:
eip: kh1-eip
internalCIDR: 192.168.10.0/24
EOF
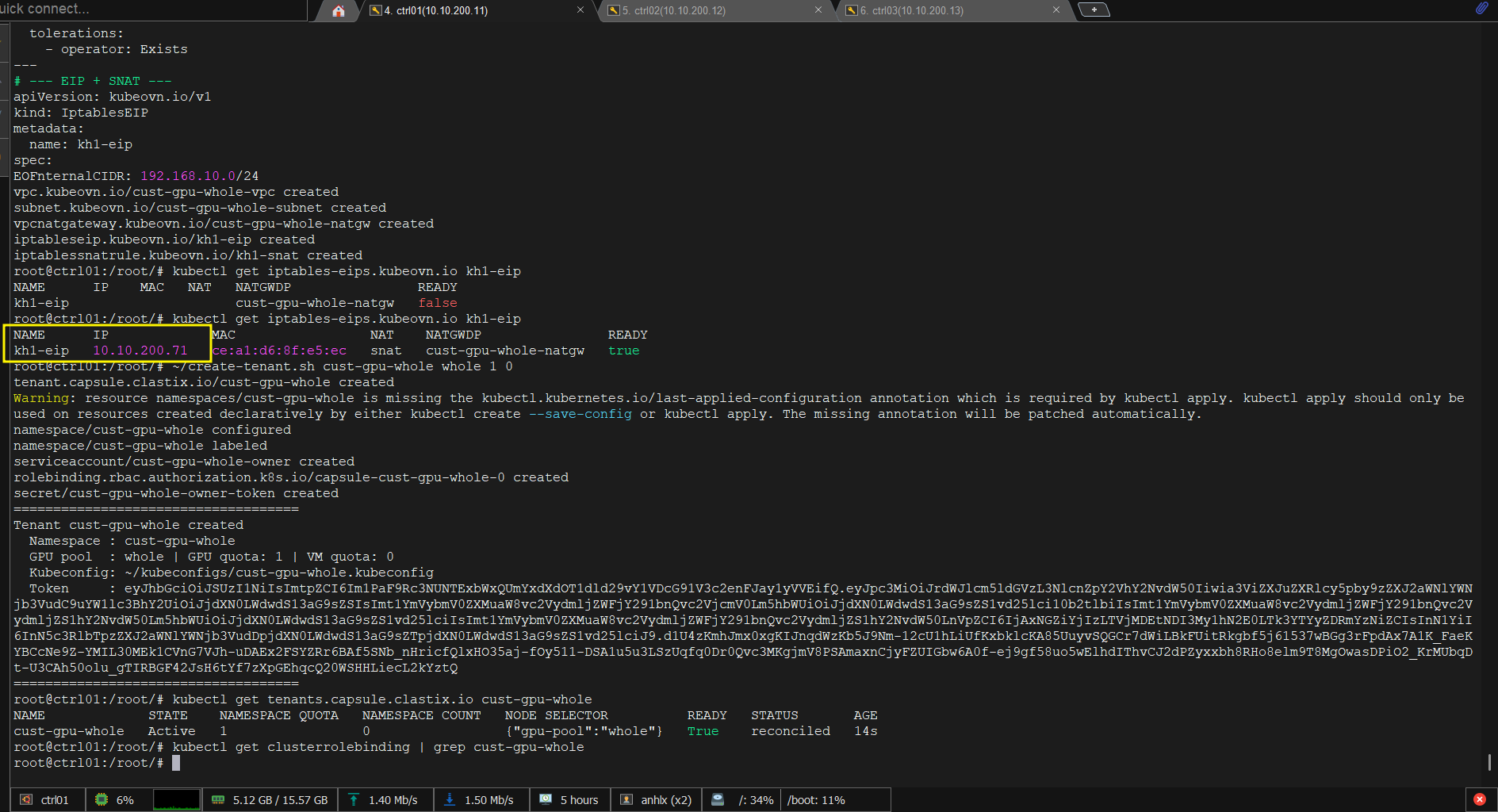
kubectl get iptables-eips.kubeovn.io kh1-eip
# NAME IP READY
# kh1-eip 10.10.200.71 true
11.2.2 Tạo Tenant (Capsule + kubeconfig)
# gpu-pool=whole: container land trên ctrl01, gpu-quota=1 (1 GPU nguyên), vm-quota=0
~/create-tenant.sh cust-gpu-whole whole 1 0
Verify:
kubectl get tenants.capsule.clastix.io cust-gpu-whole
# NAME STATE NAMESPACE QUOTA NAMESPACE COUNT
# cust-gpu-whole Active 1 1
kubectl get clusterrolebinding | grep cust-gpu-whole
# (empty)
11.2.3 Deploy container CUDA nguyên GPU + verify
Mình pin IP 192.168.10.11 qua annotation để tạo DNAT ổn định:
export KUBECONFIG=~/rke2.yaml
kubectl apply -f - <<EOF
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cust-gpu-whole-data
namespace: cust-gpu-whole
spec:
accessModes: [ReadWriteOnce]
storageClassName: rook-ceph-block
resources:
requests:
storage: 10Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: cust-gpu-whole-app
namespace: cust-gpu-whole
labels:
customer: cust-gpu-whole
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: cust-gpu-whole-app
template:
metadata:
labels:
app: cust-gpu-whole-app
customer: cust-gpu-whole
annotations:
ovn.kubernetes.io/ip_address: "192.168.10.11"
ovn.kubernetes.io/logical_switch: "cust-gpu-whole-subnet"
spec:
dnsPolicy: "None"
dnsConfig:
nameservers:
- 8.8.8.8
nodeSelector:
gpu-pool: whole
containers:
- name: cuda
image: nvcr.io/nvidia/cuda:12.6.0-base-ubuntu22.04
command: ["sh", "-c"]
args:
- |
apt-get update -qq && apt-get install -qq -y openssh-server
mkdir -p /run/sshd
echo 'root:<password>' | chpasswd
sed -i 's/#PermitRootLogin .*/PermitRootLogin yes/' /etc/ssh/sshd_config
sed -i 's/#PasswordAuthentication.*/PasswordAuthentication yes/' /etc/ssh/sshd_config
/usr/sbin/sshd -D
resources:
requests:
cpu: 500m
memory: 1Gi
nvidia.com/gpu: 1
limits:
cpu: 2
memory: 2Gi
nvidia.com/gpu: 1
ports:
- containerPort: 22
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
persistentVolumeClaim:
claimName: cust-gpu-whole-data
EOF
kubectl get pods -n cust-gpu-whole -o wide
# NAME IP NODE
# cust-gpu-whole-app-xxxxx 192.168.10.11 ctrl01
Tạo DNAT SSH vào container:
kubectl apply -f - <<EOF
apiVersion: kubeovn.io/v1
kind: IptablesDnatRule
metadata:
name: kh1-ssh-dnat
spec:
eip: kh1-eip
externalPort: "22"
protocol: TCP
internalIp: 192.168.10.11
internalPort: "22"
EOF
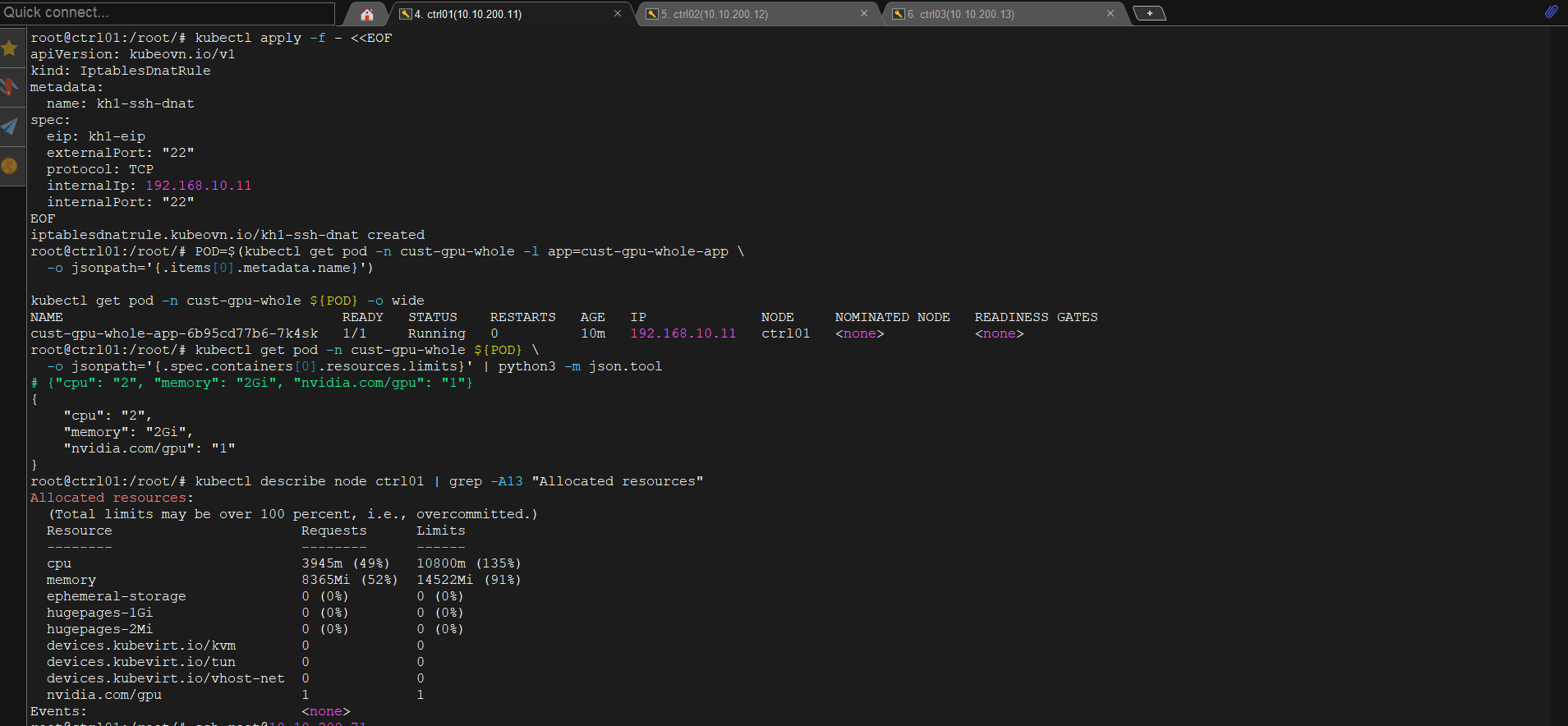
Verify GPU resource:
POD=$(kubectl get pod -n cust-gpu-whole -l app=cust-gpu-whole-app \
-o jsonpath='{.items[0].metadata.name}')
kubectl get pod -n cust-gpu-whole ${POD} -o wide
# NAME IP NODE
# cust-gpu-whole-app-xxxxx 192.168.10.11 ctrl01
kubectl get pod -n cust-gpu-whole ${POD} \
-o jsonpath='{.spec.containers[0].resources.limits}' | python3 -m json.tool
# {"cpu": "2", "memory": "2Gi", "nvidia.com/gpu": "1"}
# Verify GPU đã được allocate trên node (nvidia.com/gpu: 1/2)
kubectl describe node ctrl01 | grep -A13 "Allocated resources"
# nvidia.com/gpu 1 1
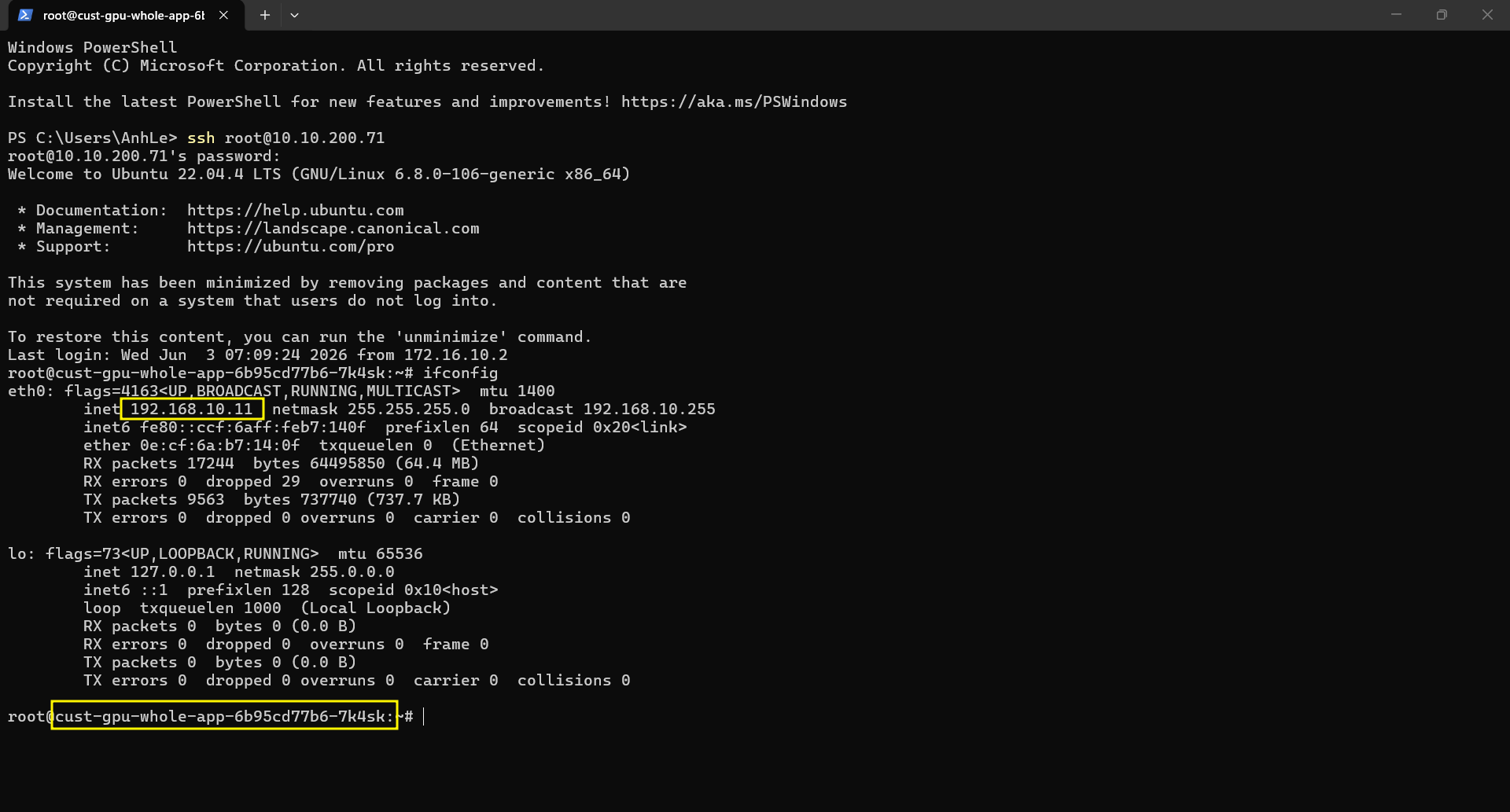
ssh root@10.10.200.71
# root@cust-gpu-whole-app-xxxxx:~#
11.3 KH2 — Container CUDA 2 GPU chia nhỏ
Khách hàng: research team chạy nhiều inference job nhỏ song song — 2 GPU slice từ shared pool là đủ, tiết kiệm chi phí hơn nguyên GPU.
11.3.1 Tạo VPC + Subnet + NAT Gateway + EIP
export KUBECONFIG=~/rke2.yaml
kubectl create namespace cust-gpu-shared
kubectl apply -f - <<EOF
# --- VPC ---
apiVersion: kubeovn.io/v1
kind: Vpc
metadata:
name: cust-gpu-shared-vpc
spec:
namespaces:
- cust-gpu-shared
---
# --- Subnet (namespace binding — pod tự nhận VPC IP, không cần NAD) ---
apiVersion: kubeovn.io/v1
kind: Subnet
metadata:
name: cust-gpu-shared-subnet
spec:
vpc: cust-gpu-shared-vpc
protocol: IPv4
cidrBlock: 192.168.20.0/24
gateway: 192.168.20.254
excludeIps:
- 192.168.20.254
enableDHCP: true
namespaces:
- cust-gpu-shared
dhcpV4Options: "lease_time=3600,router=192.168.20.254,server_id=192.168.20.254,dns_server=8.8.8.8"
---
# --- NAT Gateway ---
apiVersion: kubeovn.io/v1
kind: VpcNatGateway
metadata:
name: cust-gpu-shared-natgw
spec:
vpc: cust-gpu-shared-vpc
subnet: cust-gpu-shared-subnet
lanIp: 192.168.20.254
selector:
- "kubernetes.io/os: linux"
tolerations:
- operator: Exists
---
# --- EIP + SNAT ---
apiVersion: kubeovn.io/v1
kind: IptablesEIP
metadata:
name: kh2-eip
spec:
v4ip: 10.10.200.72
natGwDp: cust-gpu-shared-natgw
---
apiVersion: kubeovn.io/v1
kind: IptablesSnatRule
metadata:
name: kh2-snat
spec:
eip: kh2-eip
internalCIDR: 192.168.20.0/24
EOF
kubectl get iptables-eips.kubeovn.io kh2-eip
# NAME IP READY
# kh2-eip 10.10.200.72 true
kubectl ko nbctl lr-route-list cust-gpu-shared-vpc
# (empty)
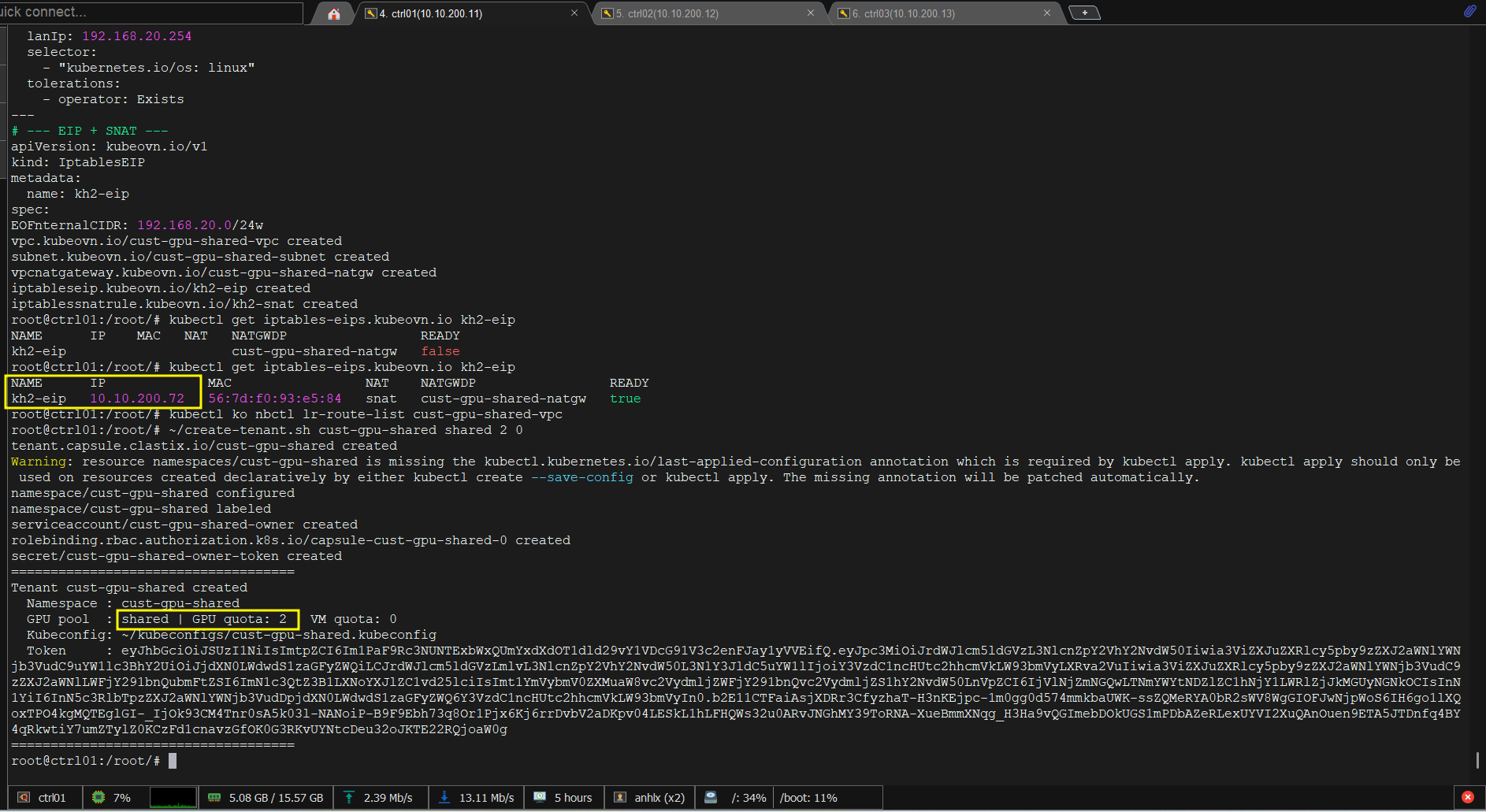
11.3.2 Tạo Tenant (Capsule + kubeconfig)
# gpu-pool=shared: container land trên ctrl02, gpu-quota=2 (2 GPU slice), vm-quota=0
~/create-tenant.sh cust-gpu-shared shared 2 0
11.3.3 Deploy container CUDA 2 GPU chia nhỏ + verify
Container request 2 GPU slice từ ctrl02 (shared pool, tổng 8 slice):
export KUBECONFIG=~/rke2.yaml
kubectl apply -f - <<EOF
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cust-gpu-shared-data
namespace: cust-gpu-shared
spec:
accessModes: [ReadWriteOnce]
storageClassName: rook-ceph-block
resources:
requests:
storage: 10Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: cust-gpu-shared-app
namespace: cust-gpu-shared
labels:
customer: cust-gpu-shared
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: cust-gpu-shared-app
template:
metadata:
labels:
app: cust-gpu-shared-app
customer: cust-gpu-shared
annotations:
ovn.kubernetes.io/ip_address: "192.168.20.11"
ovn.kubernetes.io/logical_switch: "cust-gpu-shared-subnet"
spec:
dnsPolicy: "None"
dnsConfig:
nameservers:
- 8.8.8.8
nodeSelector:
gpu-pool: shared
containers:
- name: cuda
image: nvcr.io/nvidia/cuda:12.6.0-base-ubuntu22.04
command: ["sh", "-c"]
args:
- |
apt-get update -qq && apt-get install -qq -y openssh-server
mkdir -p /run/sshd
echo 'root:<password>' | chpasswd
sed -i 's/#PermitRootLogin .*/PermitRootLogin yes/' /etc/ssh/sshd_config
sed -i 's/#PasswordAuthentication.*/PasswordAuthentication yes/' /etc/ssh/sshd_config
/usr/sbin/sshd -D
resources:
requests:
cpu: 500m
memory: 1Gi
nvidia.com/gpu: 2
limits:
cpu: 2
memory: 2Gi
nvidia.com/gpu: 2
ports:
- containerPort: 22
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
persistentVolumeClaim:
claimName: cust-gpu-shared-data
EOF
kubectl get pods -n cust-gpu-shared -o wide
# NAME IP NODE
# cust-gpu-shared-app-xxxxx 192.168.20.11 ctrl02
Tạo DNAT SSH vào container:
kubectl apply -f - <<EOF
apiVersion: kubeovn.io/v1
kind: IptablesDnatRule
metadata:
name: kh2-ssh-dnat
spec:
eip: kh2-eip
externalPort: "22"
protocol: TCP
internalIp: 192.168.20.11
internalPort: "22"
EOF
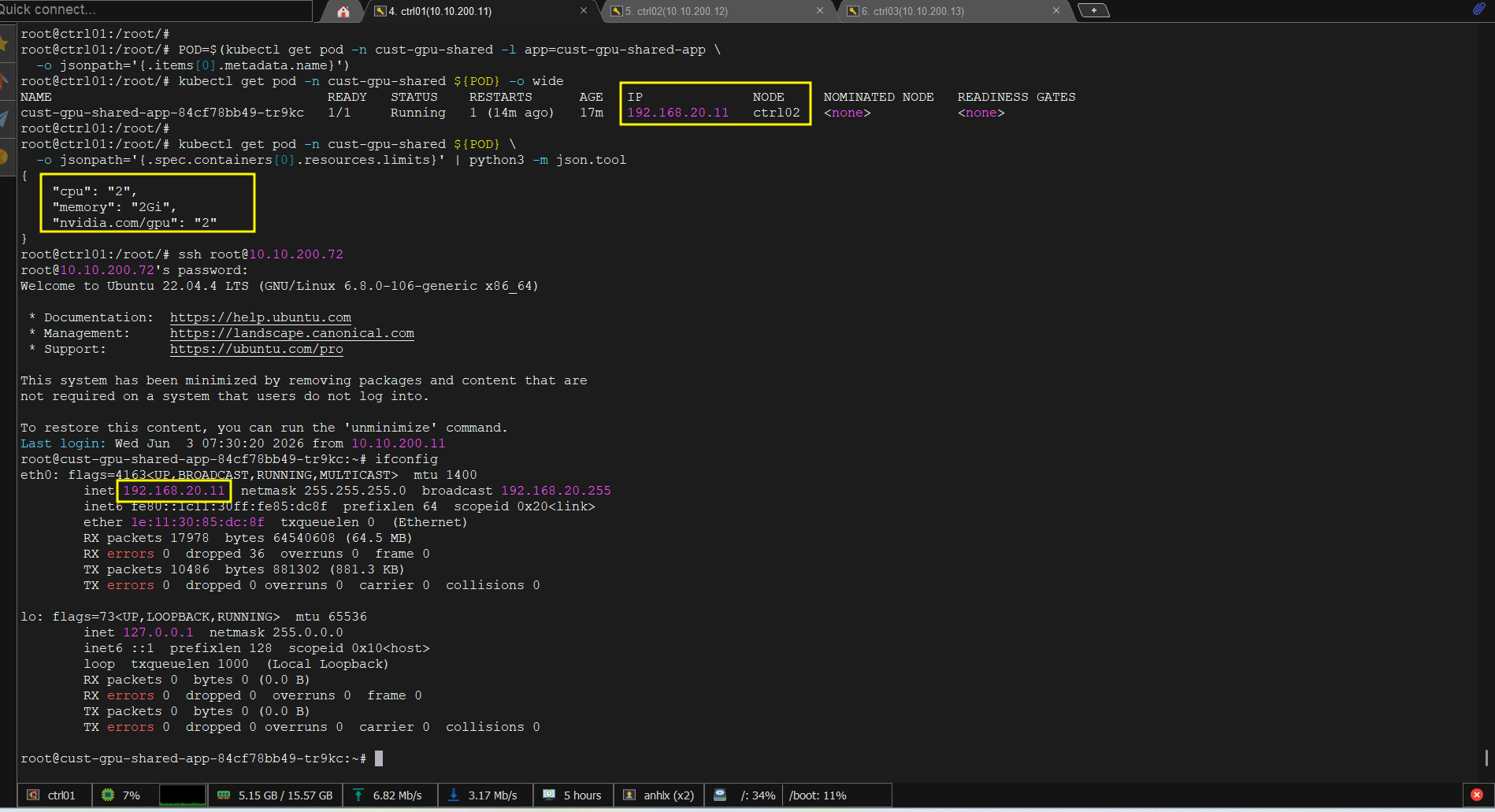
ssh root@10.10.200.72
Verify GPU resource:
POD=$(kubectl get pod -n cust-gpu-shared -l app=cust-gpu-shared-app \
-o jsonpath='{.items[0].metadata.name}')
kubectl get pod -n cust-gpu-shared ${POD} -o wide
# NAME IP NODE
# cust-gpu-shared-app-xxxxx 192.168.20.11 ctrl02
kubectl get pod -n cust-gpu-shared ${POD} \
-o jsonpath='{.spec.containers[0].resources.limits}' | python3 -m json.tool
# {"cpu": "2", "memory": "2Gi", "nvidia.com/gpu": "2"}
11.4 KH3 — VM Ubuntu + VM Windows (không GPU)
Khách hàng: văn phòng cần môi trường dev Ubuntu và Windows Server để chạy ứng dụng doanh nghiệp, không có nhu cầu GPU — dùng ctrl03 CPU-only node.
11.4.1 Tạo VPC + Subnet + NAT Gateway + EIP + NAD
Mình tạo namespace trước vì NAD cần namespace tồn tại, sau đó apply toàn bộ network stack:
export KUBECONFIG=~/rke2.yaml
kubectl create namespace cust-cpu
kubectl apply -f - <<EOF
# --- VPC ---
apiVersion: kubeovn.io/v1
kind: Vpc
metadata:
name: cust-cpu-vpc
spec:
namespaces:
- cust-cpu
---
# --- Subnet ---
apiVersion: kubeovn.io/v1
kind: Subnet
metadata:
name: cust-cpu-subnet
spec:
vpc: cust-cpu-vpc
protocol: IPv4
cidrBlock: 192.168.30.0/24
gateway: 192.168.30.254
excludeIps:
- 192.168.30.1..192.168.30.10
- 192.168.30.254
enableDHCP: true
dhcpV4Options: "lease_time=3600,router=192.168.30.254,server_id=192.168.30.254,dns_server=8.8.8.8"
provider: cust-cpu-nad.cust-cpu.ovn
---
# --- NAT Gateway ---
apiVersion: kubeovn.io/v1
kind: VpcNatGateway
metadata:
name: cust-cpu-natgw
spec:
vpc: cust-cpu-vpc
subnet: cust-cpu-subnet
lanIp: 192.168.30.254
selector:
- "kubernetes.io/os: linux"
tolerations:
- operator: Exists
---
# --- EIP + SNAT ---
apiVersion: kubeovn.io/v1
kind: IptablesEIP
metadata:
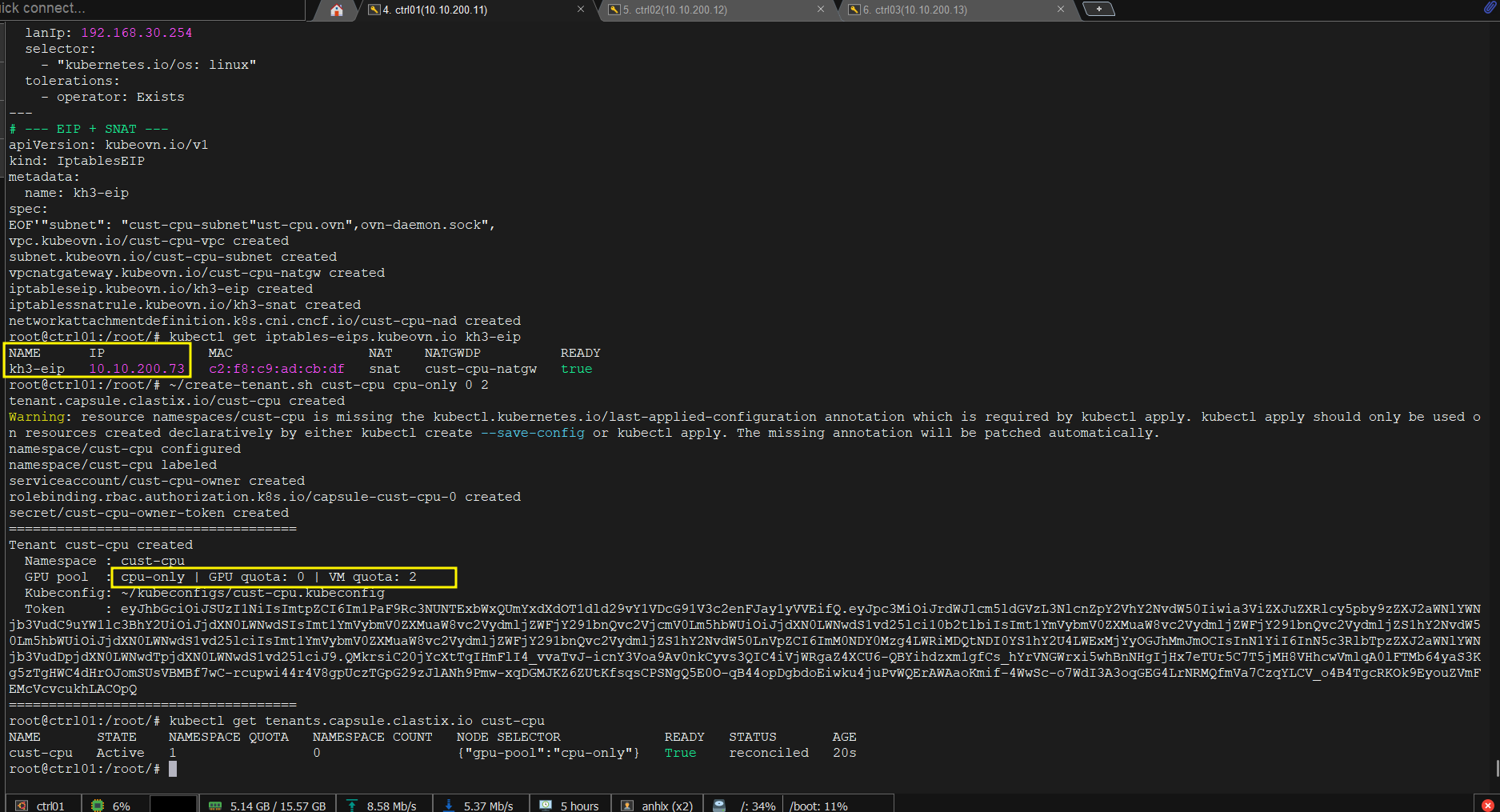
name: kh3-eip
spec:
v4ip: 10.10.200.73
natGwDp: cust-cpu-natgw
---
apiVersion: kubeovn.io/v1
kind: IptablesSnatRule
metadata:
name: kh3-snat
spec:
eip: kh3-eip
internalCIDR: 192.168.30.0/24
---
# --- NAD cho VM secondary NIC ---
apiVersion: k8s.cni.cncf.io/v1
kind: NetworkAttachmentDefinition
metadata:
name: cust-cpu-nad
namespace: cust-cpu
spec:
config: '{
"cniVersion": "0.3.1",
"type": "kube-ovn",
"server_socket": "/run/openvswitch/kube-ovn-daemon.sock",
"provider": "cust-cpu-nad.cust-cpu.ovn",
"subnet": "cust-cpu-subnet"
}'
EOF
kubectl get iptables-eips.kubeovn.io kh3-eip
# NAME IP READY
# kh3-eip 10.10.200.73 true
11.4.2 Tạo Tenant (Capsule + kubeconfig)
# gpu-pool=cpu-only: VM land trên ctrl03, gpu-quota=0, vm-quota=2 (Ubuntu + Windows)
~/create-tenant.sh cust-cpu cpu-only 0 2
Verify:
kubectl get tenants.capsule.clastix.io cust-cpu
# NAME STATE NAMESPACE QUOTA NAMESPACE COUNT
# cust-cpu Active 1 1
11.4.3 Provision VM Ubuntu + verify
Admin clone golden image vào namespace của KH3:
export KUBECONFIG=~/rke2.yaml
kubectl apply -f - <<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: cdi-cloner
namespace: vm-images
subjects:
- kind: ServiceAccount
name: default
namespace: cust-cpu
roleRef:
kind: ClusterRole
name: edit
apiGroup: rbac.authorization.k8s.io
---
apiVersion: cdi.kubevirt.io/v1beta1
kind: DataVolume
metadata:
name: ubuntu-2204-img
namespace: cust-cpu
spec:
source:
pvc:
namespace: vm-images
name: ubuntu-2204-golden
storage:
accessModes: [ReadWriteMany]
volumeMode: Filesystem
resources:
requests:
storage: 10Gi
storageClassName: rook-cephfs
EOF
kubectl get dv -n cust-cpu ubuntu-2204-img -w
# ubuntu-2204-img Succeeded 100.0%
Admin deploy VM Ubuntu cho KH3:
PASSWD_HASH=$(openssl passwd -6 '123456')
kubectl apply -f - <<EOF
---
apiVersion: v1
kind: Secret
metadata:
name: ubuntu-cloudinit
namespace: cust-cpu
type: Opaque
stringData:
userdata: |
#cloud-config
hostname: cust-cpu-vm
users:
- name: ubuntu
sudo: ALL=(ALL) NOPASSWD:ALL
shell: /bin/bash
lock_passwd: false
passwd: ${PASSWD_HASH}
ssh_pwauth: true
write_files:
- path: /etc/netplan/99-ovn-routes.yaml
permissions: '0600'
content: |
network:
version: 2
ethernets:
enp1s0:
dhcp4: true
dhcp6: false
dhcp4-overrides:
use-routes: false
routes:
- to: default
via: 192.168.30.254
nameservers:
addresses: [8.8.8.8]
runcmd:
- apt-get install -y qemu-guest-agent
- systemctl enable --now qemu-guest-agent
- systemctl enable --now ssh
- netplan apply
- echo "KH3 lab cust-cpu — Ubuntu 22.04 VM ready" > /etc/motd
---
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: cust-cpu-vm
namespace: cust-cpu
labels:
customer: cust-cpu
spec:
runStrategy: Always
instancetype:
name: lab.u1.small.1x2
preference:
name: ubuntu
template:
metadata:
labels:
customer: cust-cpu
kubevirt.io/vm: cust-cpu-vm
annotations:
k8s.v1.cni.cncf.io/networks: '[{"name":"cust-cpu-nad","interface":"ovn0"}]'
spec:
nodeSelector:
gpu-pool: cpu-only
domain:
devices:
disks:
- name: rootdisk
disk:
bus: virtio
- name: cloudinitdisk
disk:
bus: virtio
interfaces:
- name: ovn-vpc
bridge: {}
networkInterfaceMultiqueue: true
networks:
- name: ovn-vpc
multus:
networkName: cust-cpu-nad
volumes:
- name: rootdisk
dataVolume:
name: ubuntu-2204-img
- name: cloudinitdisk
cloudInitNoCloud:
secretRef:
name: ubuntu-cloudinit
EOF
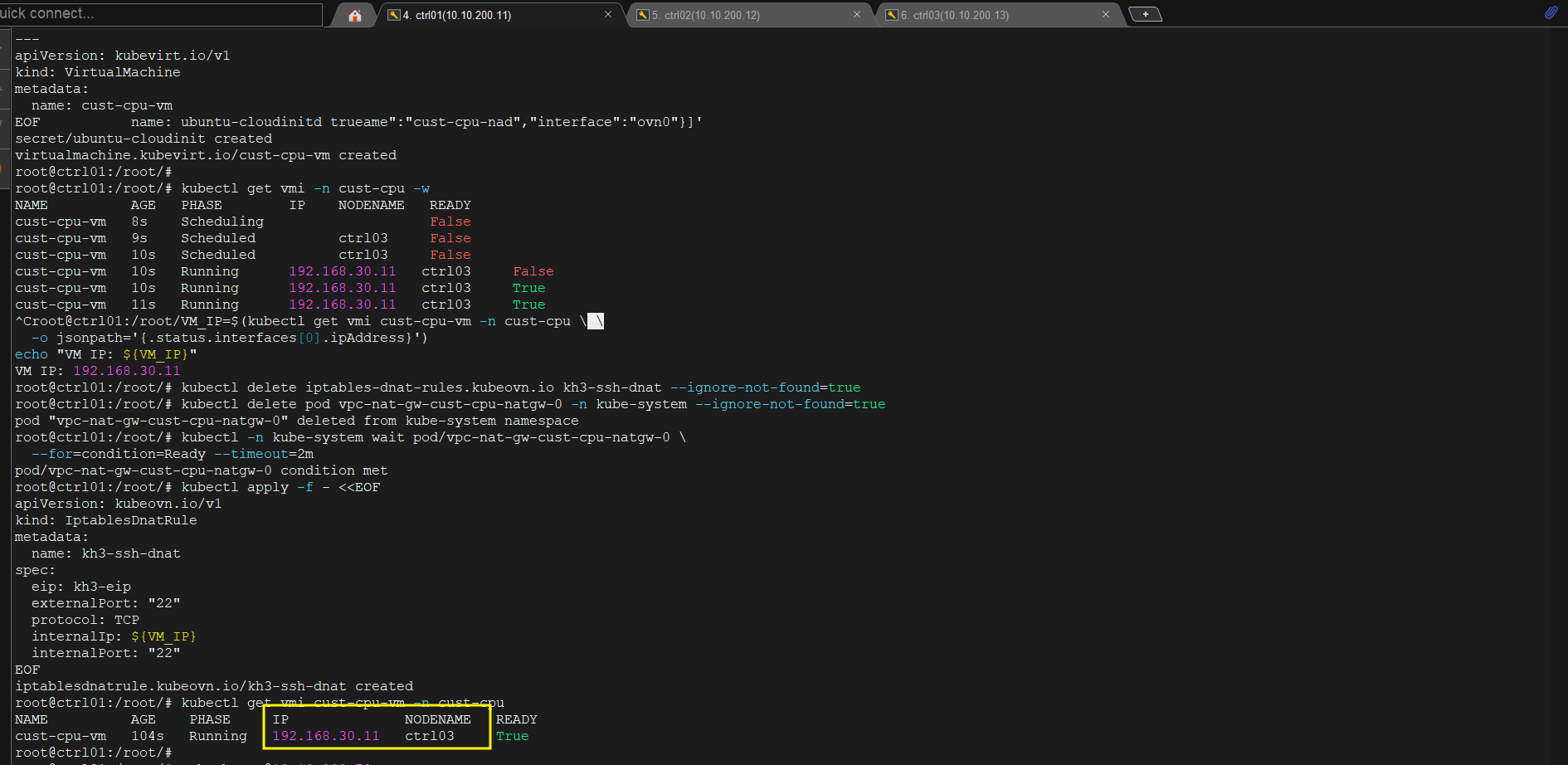
kubectl get vmi -n cust-cpu -w
# NAME AGE PHASE IP NODENAME READY
# cust-cpu-vm 68s Running 192.168.30.1x ctrl03 True
Associate floating IP — DNAT SSH Ubuntu VM:
VM_IP=$(kubectl get vmi cust-cpu-vm -n cust-cpu \
-o jsonpath='{.status.interfaces[?(@.name=="ovn-vpc")].ipAddress}')
echo "VM IP: ${VM_IP}"
kubectl delete iptables-dnat-rules.kubeovn.io kh3-ssh-dnat --ignore-not-found=true
kubectl apply -f - <<EOF
apiVersion: kubeovn.io/v1
kind: IptablesDnatRule
metadata:
name: kh3-ssh-dnat
spec:
eip: kh3-eip
externalPort: "22"
protocol: TCP
internalIp: ${VM_IP}
internalPort: "22"
EOF
kubectl get iptables-dnat-rules.kubeovn.io kh3-ssh-dnat
# NAME EIP PROTOCOL INTERNALIP EXTERNALPORT READY
# kh3-ssh-dnat kh3-eip TCP 192.168.30.x 22 true
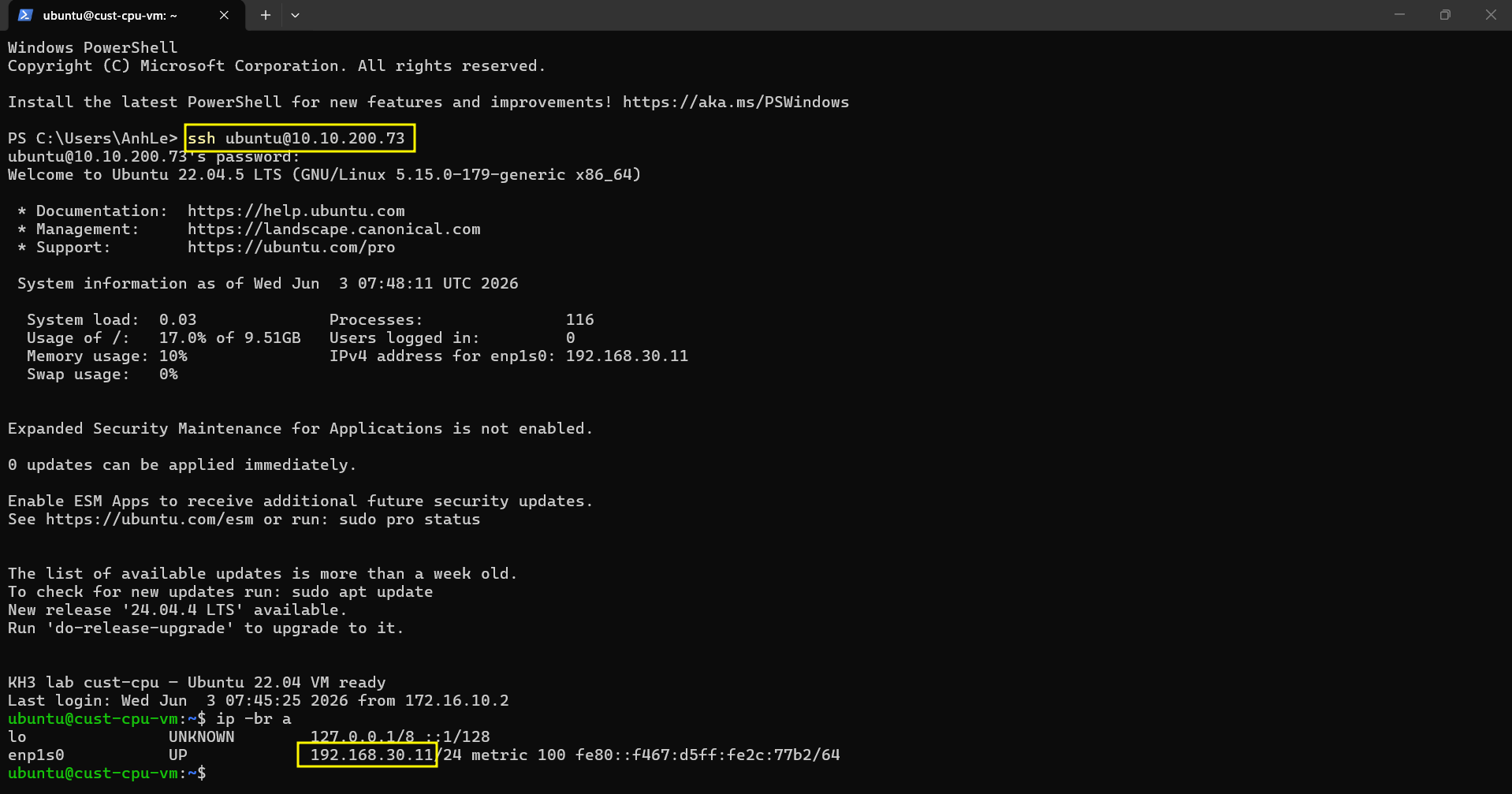
Verify VM land đúng ctrl03 và SSH qua EIP:
kubectl get vmi cust-cpu-vm -n cust-cpu
# NAME AGE PHASE IP NODENAME READY
# cust-cpu-vm 69s Running 192.168.30.x ctrl03 True
ssh ubuntu@10.10.200.73
Serial console (recover khi network mất):
virtctl console cust-cpu-vm -n cust-cpu --kubeconfig=/root/kubeconfigs/cust-cpu.kubeconfig
11.4.4 Provision VM Windows + verify
Admin clone Windows golden image vào namespace KH3:
export KUBECONFIG=~/rke2.yaml
kubectl apply -f - <<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: cdi-cloner-win
namespace: vm-images
subjects:
- kind: ServiceAccount
name: default
namespace: cust-cpu
roleRef:
kind: ClusterRole
name: edit
apiGroup: rbac.authorization.k8s.io
---
apiVersion: cdi.kubevirt.io/v1beta1
kind: DataVolume
metadata:
name: windows-2022-rootdisk
namespace: cust-cpu
spec:
source:
pvc:
namespace: vm-images
name: windows-2022-golden
storage:
accessModes: [ReadWriteMany]
volumeMode: Block
resources:
requests:
storage: 60Gi
storageClassName: rook-ceph-block-rwx
EOF
kubectl get dv -n cust-cpu windows-2022-rootdisk -w
Admin deploy VM Windows cho KH3:
kubectl apply -f - <<EOF
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: cust-cpu-win
namespace: cust-cpu
labels:
customer: cust-cpu
spec:
runStrategy: Manual
instancetype:
name: lab.win.4x6
preference:
name: windows.2k22
template:
metadata:
labels:
customer: cust-cpu
kubevirt.io/vm: cust-cpu-win
annotations:
k8s.v1.cni.cncf.io/networks: '[{"name":"cust-cpu-nad","interface":"ovn0"}]'
spec:
nodeSelector:
gpu-pool: cpu-only
domain:
firmware:
uuid: "$(uuidgen)"
bootloader:
efi:
secureBoot: false
devices:
tpm: {}
disks:
- name: rootdisk
disk:
bus: virtio
interfaces:
- name: ovn-vpc
bridge: {}
model: e1000
networks:
- name: ovn-vpc
multus:
networkName: cust-cpu-nad
volumes:
- name: rootdisk
persistentVolumeClaim:
claimName: windows-2022-rootdisk
EOF
Start VM, mở VNC để hoàn tất OOBE:
virtctl start cust-cpu-win -n cust-cpu
kubectl get vmi -n cust-cpu cust-cpu-win
# NAME PHASE IP NODE
# cust-cpu-win Running 192.168.30.x ctrl03
Sau khi OOBE hoàn tất và vào được Desktop, mở PowerShell (Admin) trong VNC console để fix 2 vấn đề sau sysprep:
# 1. OVN DHCP không push default gateway vào Windows — set persistent route
route add 0.0.0.0 mask 0.0.0.0 192.168.30.254 -p
# 2. Sau sysprep Windows classify network là Public → RDP firewall rule chỉ allow LocalSubnet
# Mở cho phép kết nối từ bất kỳ source nào
Get-NetFirewallRule -DisplayGroup "Remote Desktop" | ForEach-Object {
Set-NetFirewallRule -Name $_.Name -RemoteAddress Any -Enabled True -Profile Any
}
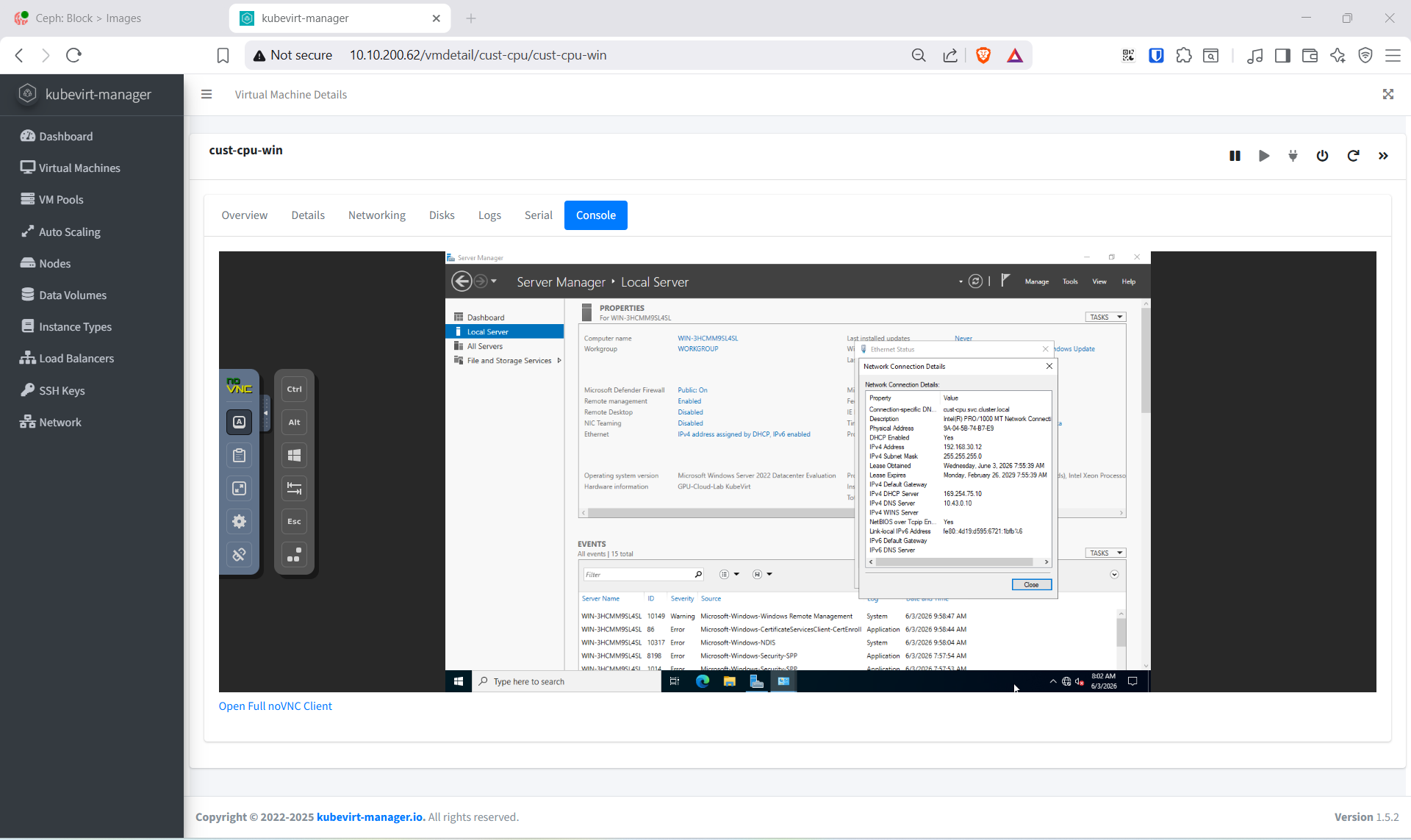
Lấy IP và tạo DNAT RDP:
export KUBECONFIG=~/rke2.yaml
WIN_IP=$(kubectl get vmi cust-cpu-win -n cust-cpu \
-o jsonpath='{.status.interfaces[?(@.name=="ovn-vpc")].ipAddress}')
echo "Windows VM IP: ${WIN_IP}"
kubectl delete iptables-dnat-rules.kubeovn.io kh3-rdp-dnat --ignore-not-found=true
kubectl apply -f - <<EOF
apiVersion: kubeovn.io/v1
kind: IptablesDnatRule
metadata:
name: kh3-rdp-dnat
spec:
eip: kh3-eip
externalPort: "3389"
protocol: TCP
internalIp: ${WIN_IP}
internalPort: "3389"
EOF
kubectl get iptables-dnat-rules.kubeovn.io kh3-rdp-dnat
# NAME EIP PROTOCOL INTERNALIP EXTERNALPORT READY
# kh3-rdp-dnat kh3-eip TCP 192.168.30.x 3389 true
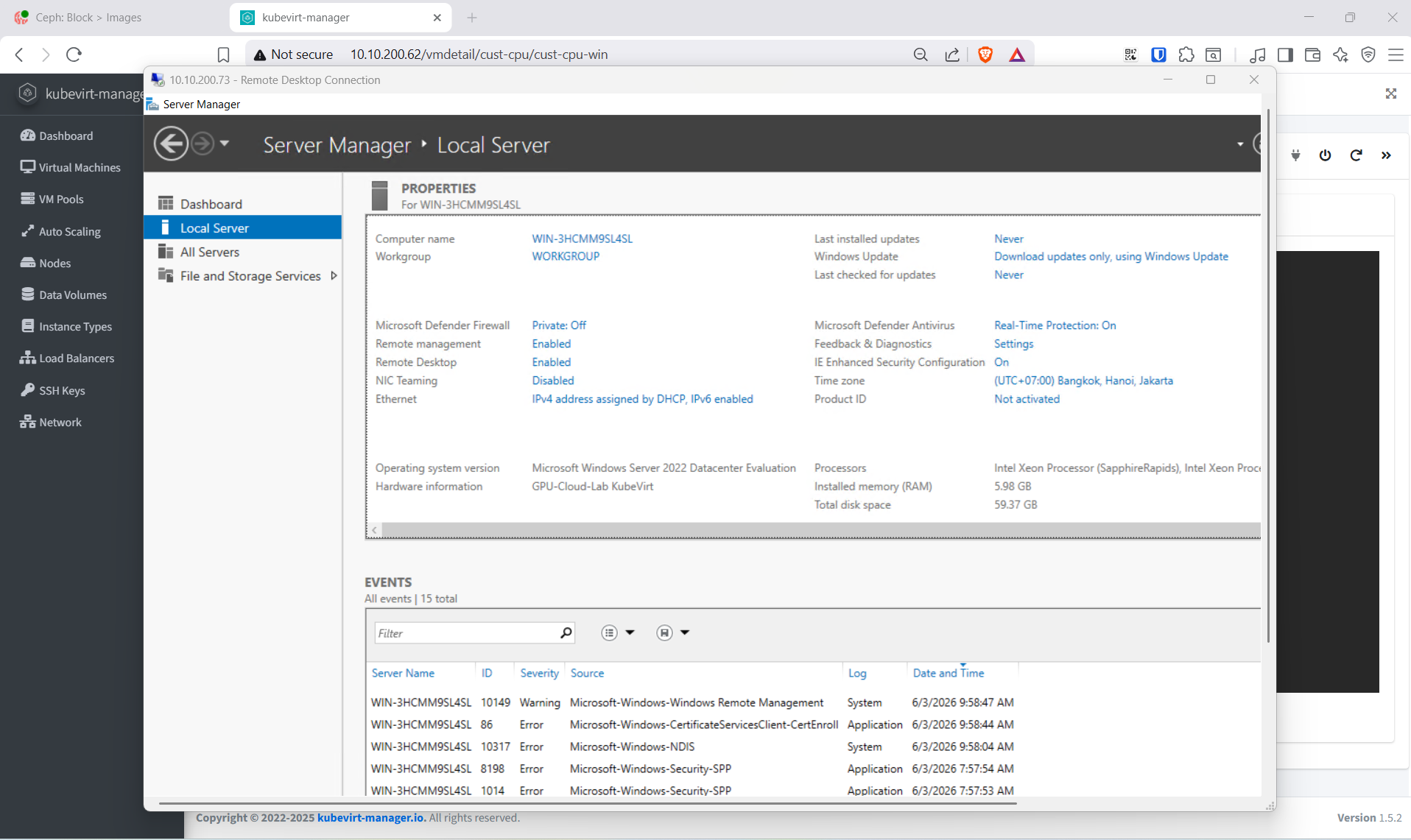
Verify:
kubectl get vm,vmi -n cust-cpu -o wide
mstsc /v:10.10.200.73
12. Service URLs & Credentials
| Service | URL / Endpoint | Credentials |
|---|---|---|
| Kubernetes API (VIP) | https://10.10.200.51:6443 | Admin: ~/rke2.yaml; Tenant: ~/kubeconfigs/<tenant>.kubeconfig |
| Ceph Dashboard | http://10.10.200.61:7000 | admin / kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}"\|base64 -d |
| KubeVirt Manager | http://10.10.200.62 | (SA cluster-admin, admin-only) |
| KH1 — cust-gpu-whole (CUDA Container SSH) | ssh root@10.10.200.71 port 22 |
root / <password> (set trong container args) |
| KH2 — cust-gpu-shared (CUDA Container SSH) | ssh root@10.10.200.72 port 22 |
root / <password> (set trong container args) |
| KH3 — cust-cpu (Ubuntu VM SSH) | ssh ubuntu@10.10.200.73 port 22 |
ubuntu / <your-password> (set trong cloud-init) |
| KH3 — cust-cpu (Windows VM RDP) | mstsc /v:10.10.200.73 port 3389 |
Administrator / <oobe-password> |
Port quan trọng phải mở giữa các node:
| Port | Protocol | Mục đích |
|---|---|---|
| 6443 | TCP | Kubernetes API |
| 9345 | TCP | RKE2 supervisor (node join) |
| 2379-2380 | TCP | etcd |
| 10250 | TCP | kubelet |
| 6081 | UDP | Geneve (Kube-OVN tunnel, thay VXLAN) |
| 4240 | TCP | Kube-OVN health check |
| 3300, 6789 | TCP | Ceph mon |
| 6800-7300 | TCP | Ceph OSD |
13. Lời kết
Lab này demo full pattern của một Next-Gen GPU Cloud thương mại trên Kubernetes, với trọng tâm là onboard khách hàng theo từng bước rõ ràng: mạng riêng → tenant access → provision workload. Cả 3 khách hàng — KH1 với container CUDA nguyên GPU trên ctrl01, KH2 với container CUDA 2 GPU chia nhỏ trên ctrl02, KH3 với VM Ubuntu và VM Windows không GPU trên ctrl03 — chạy song song trên cùng một cluster, mỗi tenant có VPC riêng, quota riêng, không thấy tài nguyên của nhau.
Ghi chú production:
- SR-IOV + RDMA (NVIDIA Network Operator + ConnectX): cần GPU/NIC thật, không giả lập được trong lab — thêm vào khi có phần cứng A100/H100
- MIG thay time-slicing: production ưu tiên MIG (isolated memory + compute) thay time-slicing (shared memory)
- Multiple network layers: production chạy 3 mặt phẳng tách biệt
- Kube-OVN + Cilium: không loại trừ nhau — production có thể chạy Kube-OVN cho VPC isolation và Cilium secondary cho L7 NetworkPolicy + Hubble observability